
Storing more with less: Memory Efficiency in Valkey 8
Valkey 8.0 GA is around the corner and one of the themes is increasing overall memory efficiency. Memory overhead reduction has the obvious effect of better resource utilization, but also impacts performance. By minimizing unnecessary memory consumption, you can store more data with the same hardware resources and improve overall system responsiveness. This post is going to give an overview into how Valkey internally manages the data and its memory overhead. Additionally, it talks about the two major improvements for Valkey 8.0 that improves the overall memory efficiency.
Overview
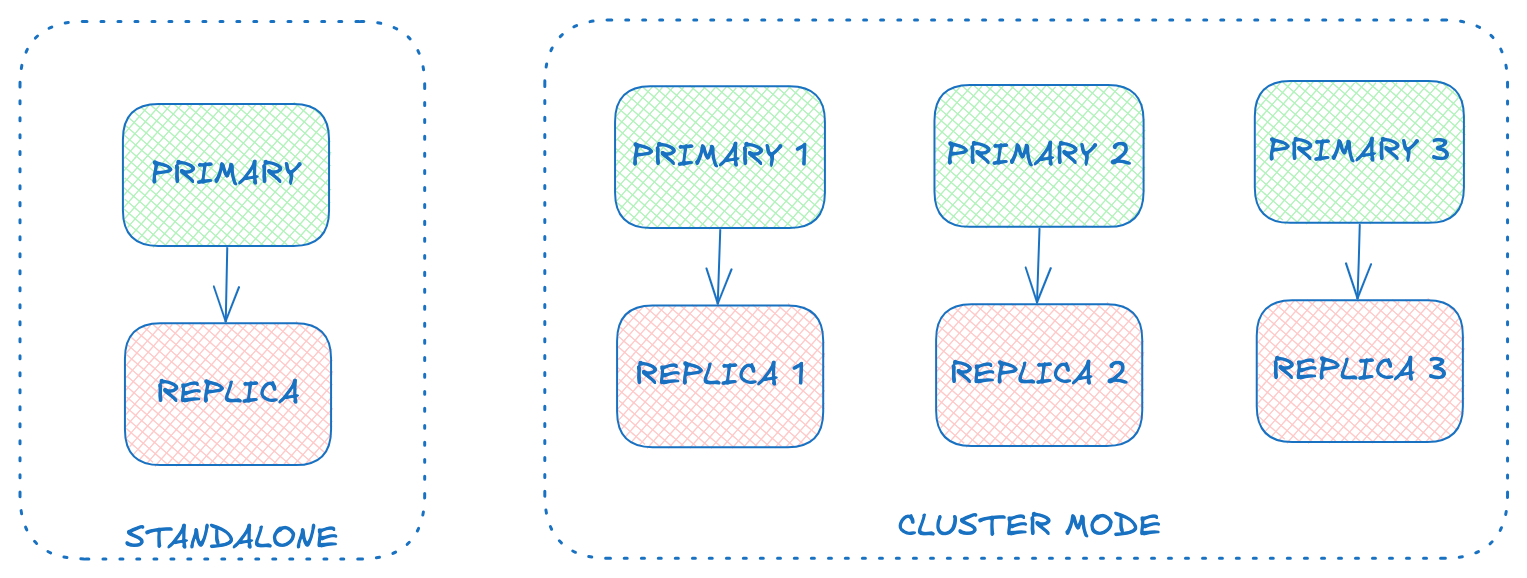
Valkey has two modes of operation: standalone and cluster mode. Standalone allows for one primary with it’s replica(s). To shard data horizontally and scale to store large amounts of data, cluster mode provides a mechanism to set up multiple primaries each with their own replica(s).
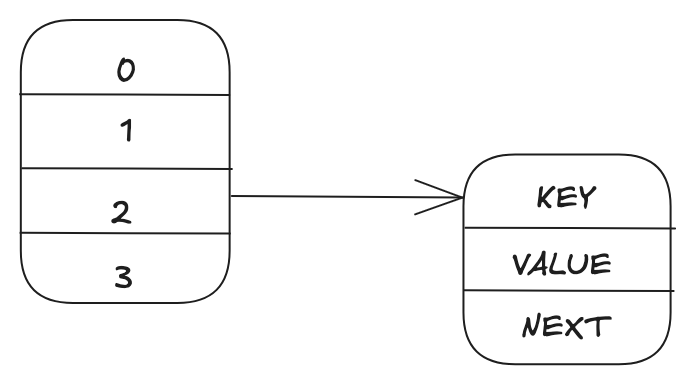
For both standalone and cluster mode setup, Valkey's main dictionary is a hash table with a chained linked list: The major components are a bucket and dictionary entry. A key is hashed to a bucket and each bucket points to a linked list of dictionary entries and further each dictionary entry consists of key, value, and a next pointer. Each pointer takes 8 bytes of memory usage. So, a single dictionary entry has a minimum overhead of 24 bytes.
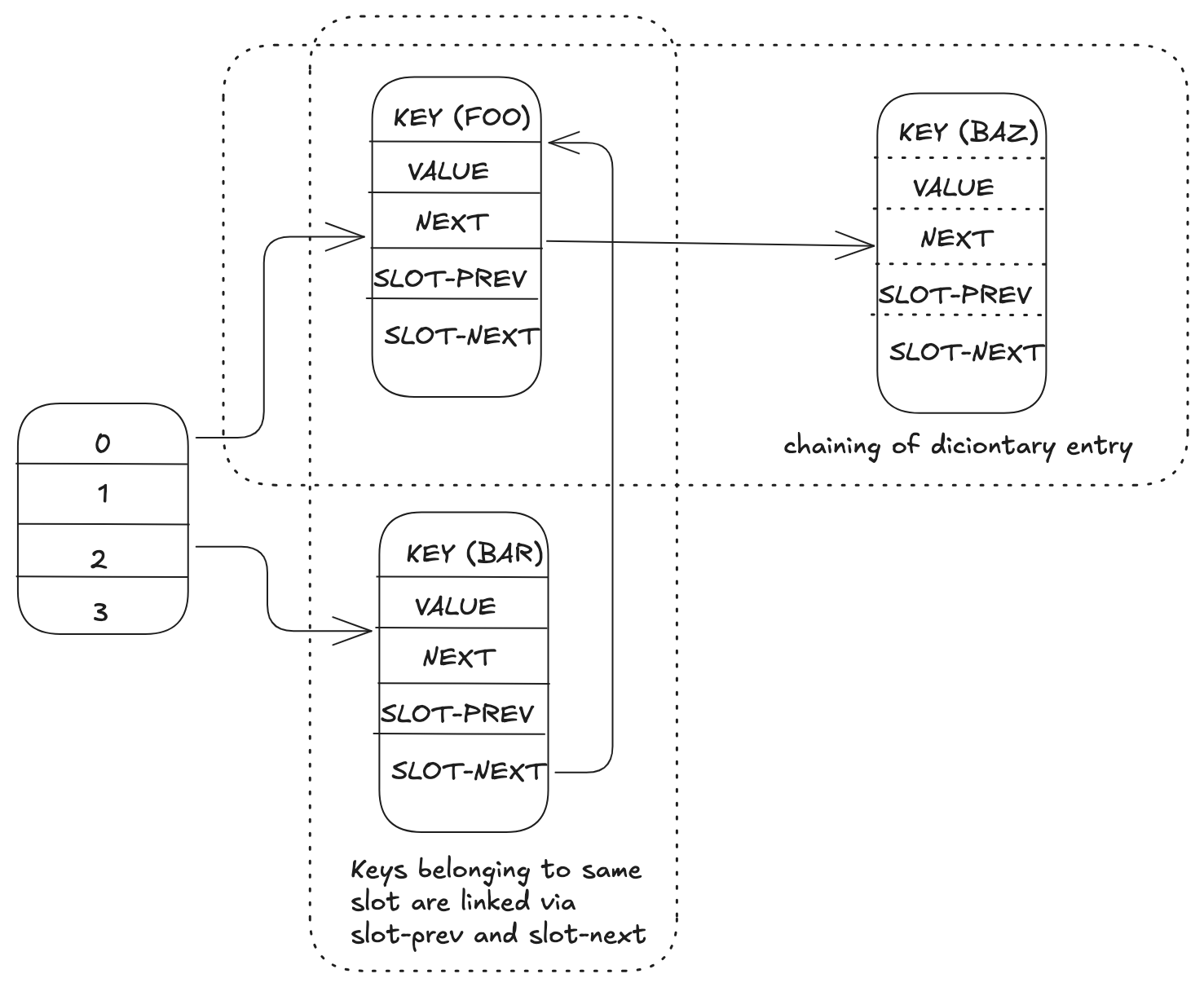
In cluster mode, Valkey uses a concept called hash slots to shard data. There are 16,384 hash slots in cluster, and to compute the hash slot for a given key, the server computes the CRC16 of the key modulo 16,384. Keys are distributed on basis of these slots assigned to each of the primary. The server needs to maintain additional metadata for bookkeeping i.e. slot-to-key mapping to move a slot from one primary to another. In order to maintain the slot to key mapping, two additional pointers slot-prev and slot-next (Figure 3) are stored as metadata in each dictionary entry forming a double linked list of all keys belonging to a given slot. This further increases the overhead by 16 bytes per dictionary entry i.e. total 40 bytes.
Improvements
Optimization 1 - Dictionary per slot
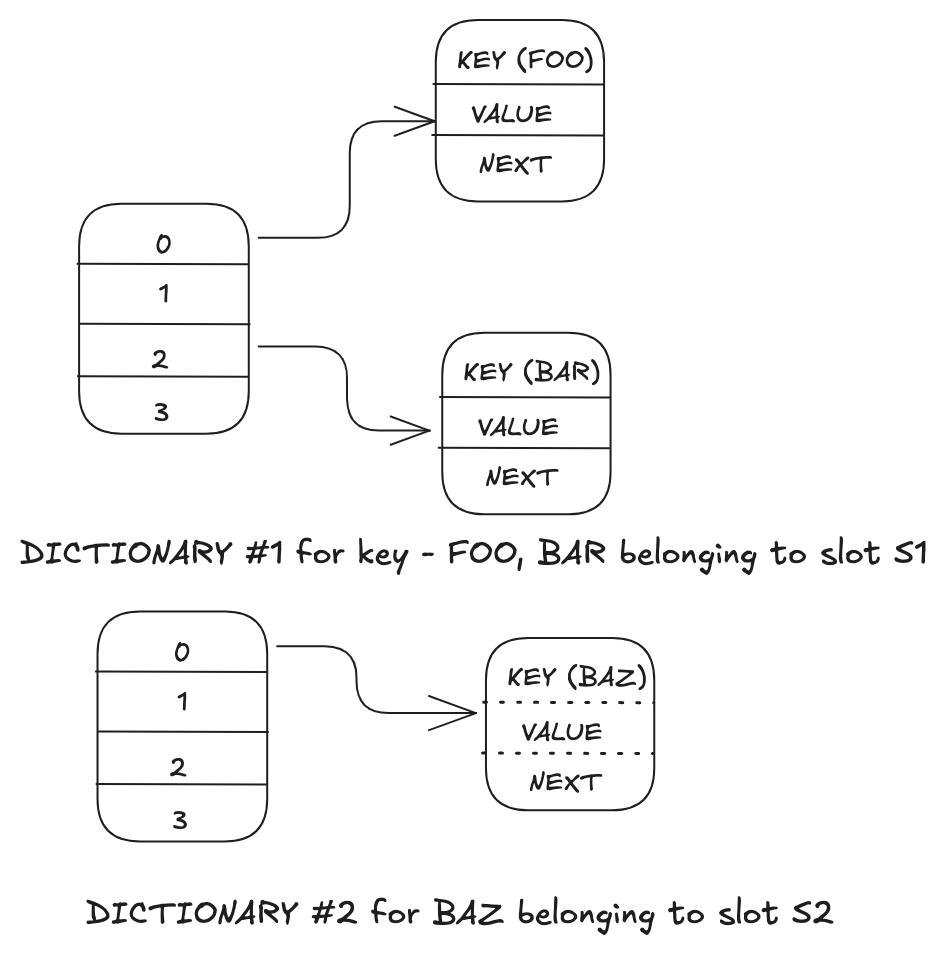
The first optimization is a dictionary per slot (16,384 of them in total), where each dictionary stores data for a given slot. With this simplification, the cost of maintaining additional metadata for the mapping of slot to key is no longer required in Valkey 8. To iterate over all the keys in a given slot, the engine simply finds out the dictionary for a given slot and traverse all the entries in it. This reduces the memory usage per dictionary entry by 16 bytes with a small memory overhead around 1 MB per node. As cluster mode is generally used for storing large amount of keys, avoiding the additional overhead per key allows users to store more number of keys in the same amount of memory.
A few of the interesting challenges that comes up with the above improvements are supporting existing use cases which were optimized with a single dictionary for the entire keyspace. The usecases are:
- Iterating the entire keyspace - Command like
SCANto iterate over the entire keyspace. - Random key for eviction - The server does random sampling of the keyspace to find ideal candidate for eviction.
- Finding a random key - Commands like
RANDOMKEYretrieve a random key from the database.
In order to efficiently implement these functions, we need to be able to both find non-empty slots, to skip over empty slots during scanning, and be able to select a random slot weighted by the number of keys that it owns. These requirements require a data structure which provides the following functionality:
- Modify value for a given slot - If a key gets added or removed, increment or decrement the value for that given slot by 1 respectively.
- Cumulative frequency until each slot - For a given number representing a key between 1 and the total number of keys, return the slot which covers the particular key.
If approached naively, the former and latter operation would take O(1) and O(N) respectively. However, we want to minimize the latter operation’s time complexity and minimally avoid in the former. Hence, a binary indexed tree (BIT) or fenwick tree which provides the above functionality with a minimal memory overhead (~1 MB per node) and the time complexity is also bounded to O(M log N) for both the operations where M = number of modification(s) and N = number of slots. This enables skipping over empty slots efficiently while iterating over the keyspace as well as finding a slot for a given key index in logarithmic time via binary search over the cumulative sum maintained by the BIT.
Another interesting side effect is on the rehashing operation. Rehashing is CPU intensive. By default, a limited number of buckets are allocated in a dictionary and it expands/shrinks dynamically based on usage. While undergoing rehashing, all the data needs to be moved from an old dictionary to a new dictionary. With Valkey 7.2, a global dictionary being shared across all the slots, all the keys get stored under a single dictionary and each time the fill factor (number of keys / number of buckets) goes above 1, the dictionary needs to move to a larger dictionary (multiple of 2) and move a large amount of keys. As this operation is performed on the fly, it causes an increase in latency for regular command operations while it's ongoing. With the per-slot dictionary optimization, the impact of rehashing is localized to the specific dictionary undergoing the process and only a subset of keys needs to be moved.
Overall, with this new approach, the benefits are:
- Removes additional memory overhead in cluster mode: Get rid of two pointers (16 bytes) per key to keep the mapping of slot to keys.
- With the rehashing operation spread out across dictionaries, CPU utilization is also spread out.
Optimization 2 - Key embedding into dictionary entry
After the dictionary per slot change, the memory layout of dictionary entry in cluster mode is the following, there are three pointers (key, value, and next). The key pointer points to a SDS (simple dynamic string) which contains the actual key data. As a key is immutable, without bringing in much complexity, it can be embedded into the dictionary entry which has the same lifetime as the former.
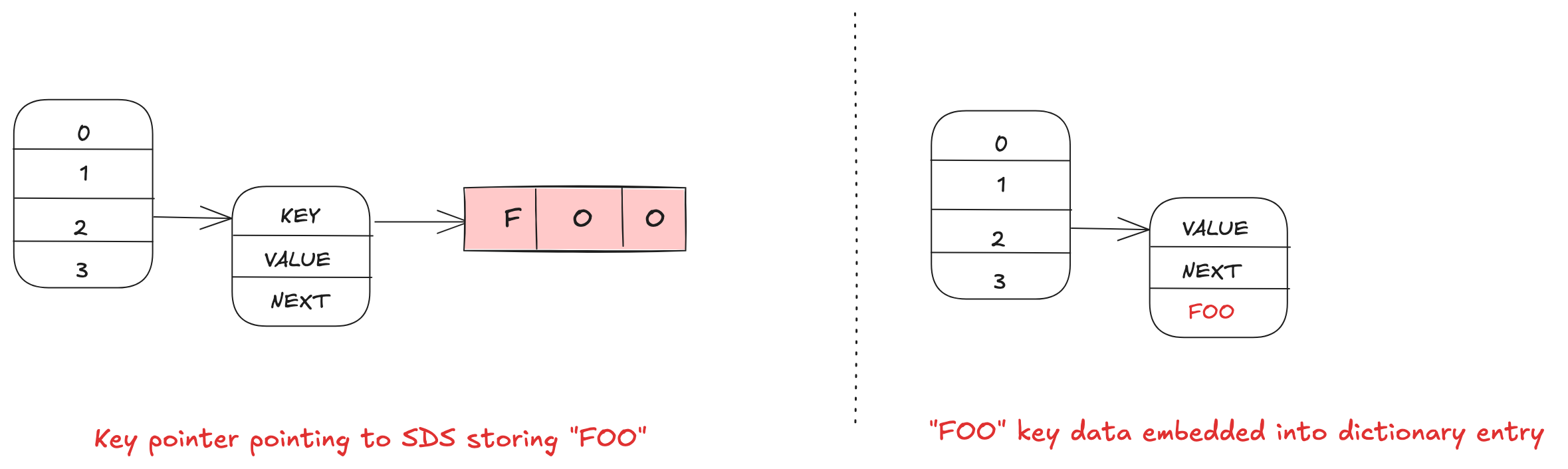
With this new approach, the overall benefits are:
- Reduces 8 bytes additional memory overhead per key.
- Removes an additional memory lookup for key: With access of dictionary entry, the additional random pointer access for key is no longer required leading to better cache locality and overall better performance.
Benchmarking
Setup
A single shard cluster is setup with 1 primary and 2 replica(s). Each node runs with different version to highlight the memory improvements with each optimization introduced between 7.2 to 8.0 and to signify that no additional configuration is required to achieve the memory efficiency.
- Node A: Primary running on port 6379 with Valkey 7.2 version
- Node B: Replica 1 running on port 6380 with optimization 1 - dictionary per slot
- Node C: Replica 2 running on port 6381 with optimization 1 - dictionary per slot and optimization 2 - key embedding - Includes all memory efficiency optimization in Valkey 8.
Synthetic data generation using valkey-benchmark utility
src/valkey-benchmark \
-t set \
-n 10000000 \
-r 10000000 \
-d 16Memory Usage
- Node A
127.0.0.1:6379> DBSIZE # command to retrieve number of keys.
(integer) 6318941
127.0.0.1:6379> INFO MEMORY # command to retrieve statistics about memory usage
# Memory
used_memory:727339288
used_memory_human:693.64M- Node B
127.0.0.1:6380> DBSIZE # command to retrieve number of keys.
(integer) 6318941
127.0.0.1:6380> INFO MEMORY # command to retrieve statistics about memory usage
# Memory
used_memory:627851888
used_memory_human:598.77M- Node C
127.0.0.1:6381> DBSIZE # command to retrieve number of keys.
(integer) 6318941
127.0.0.1:6381> INFO MEMORY # command to retrieve statistics about memory usage
# Memory
used_memory:577300952
used_memory_human:550.56MOverall Improvement
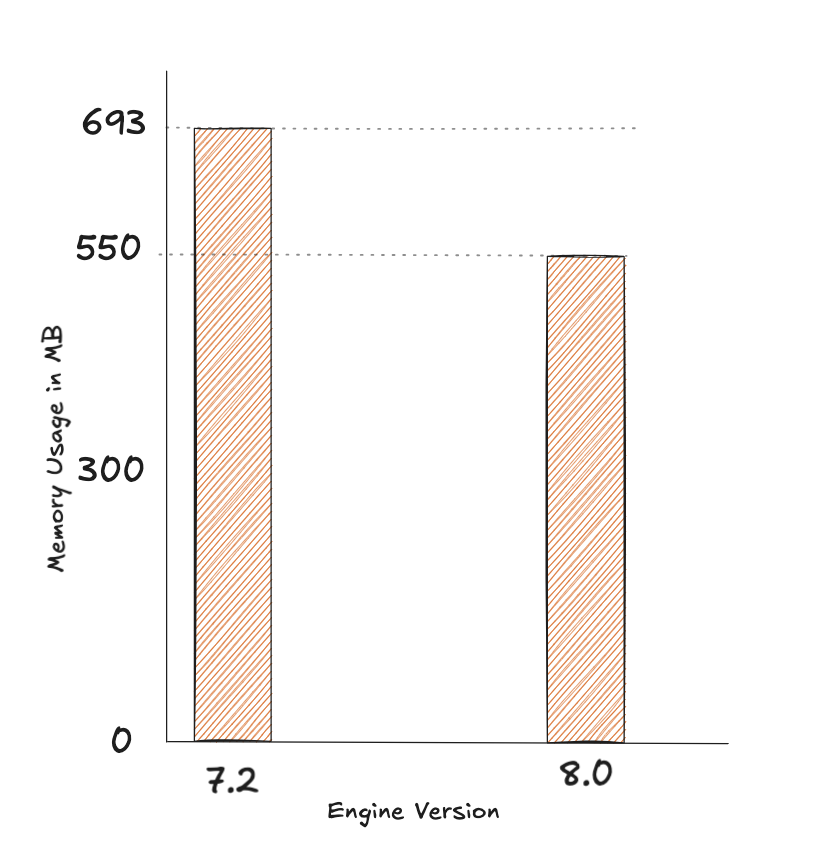
With dictionary per slot change memory usage reduced from 693.64 MB to 598.77 MB with the same dataset
- Percentage Drop 1: ((693.64 - 598.77) / 693.64) * 100 = (94.87 / 693.64) * 100 ≈ 13.68%
Further with key embedding, memory usage reduced from 598.77 MB to 550.56 MB with the same dataset
- Percentage Drop 2: ((598.77 - 550.56) / 598.77) * 100 = (48.21 / 598.77) * 100 ≈ 8.05%
Overall Drop: From 693.64 MB to 550.56 MB
- Overall Percentage Drop: ((693.64 - 550.56) / 693.64) * 100 = (143.08 / 693.64) * 100 ≈ 20.63%
So, the drop in percentage is approximately 20.63% in overall memory usage on a given node on upgrade from Valkey 7.2 to Valkey 8.0.
Conclusion
Through the memory efficiency achieved by introducing dictionary per slot and key embedding into dictionary entry, users should have additional capacity to store more keys per node in Valkey 8.0 (up to 20%, but it will vary based on the workload). For users, upgrading from Valkey 7.2 to Valkey 8.0, the improvement should be observed automatically and no configuration changes are required. Give it a try by spinning up a Valkey cluster and join us in the community to provide feedback. Further, there is an ongoing discussion around overhauling the main dictionary with a more compact memory layout and introduce an open addressing scheme which will significantly improve memory efficiency. More details can be found in Issue 169: Re-thinking the main hash table.
