
Unlock 1 Million RPS: Experience Triple the Speed with Valkey - part 2
In the first part of this blog, we described how we offloaded almost all I/O operations to I/O threads, thereby freeing more CPU cycles in the main thread to execute commands. When we profiled the execution of the main thread, we found that a considerable amount of time was spent waiting for external memory. This was not entirely surprising, as when accessing random keys, the probability of finding the key in one of the processor caches is relatively low. Considering that external memory access latency is approximately 50 times greater than L1 cache, it became clear that despite showing 100% CPU utilization, the main process was mostly “waiting”. In this blog, we describe the technique we have been using to increase the number of parallel memory accesses, thereby reducing the impact that external memory latency has on performance.
Speculative execution and linked lists
Speculative execution is a performance optimization technique used by modern processors, where the processor guesses the outcome of conditional operations and executes in parallel subsequent instructions ahead of time. Dynamic data structures, such as linked lists and search trees, have many advantages over static data structures: they are economical in memory consumption, provide fast insertion and deletion mechanisms, and can be resized efficiently. However, some dynamic data structures have a major drawback: they hinder the processor's ability to speculate on future memory load instructions that could be executed in parallel. This lack of concurrency is especially problematic in very large dynamic data structures, where most pointer accesses result in high-latency external memory access.
In this blog, Memory Access Amortization, a method that facilitates speculative execution to improve performance, is introduced along with how it is applied in Valkey. The basic idea behind the method is that by interleaving the execution of operations that access random memory locations, one can achieve significantly better performance than by executing them serially.
To depict the problem we are trying to solve consider the following function which gets an array of linked list and returns sum of all values in the lists:
unsigned long sequentialSum(size_t arr_size, list **la) {
list *lp;
unsigned long res = 0;
for (int i = 0; i < arr_size; i++) {
lp = la[i];
while (lp) {
res += lp->val;
lp = lp->next;
}
}
return res;
}Executing this function on an array of 16 lists containing 10 million elements each takes approximately 20.8 seconds on an ARM processor (Graviton 3). Now consider the following alternative implementation which instead of scanning the lists separately, interleaves the executions of the lists scans:
unsigned long interleavedSum(size_t arr_size, list **la) {
list **lthreads = malloc(arr_size * sizeof(list *));
unsigned long res = 0;
int n = arr_size;
for (int i = 0; i < arr_size; i++) {
lthreads[i] = la[i];
if (lthreads[i] == NULL)
n--;
}
while(n) {
for (int i = 0; i < arr_size; i++) {
if (lthreads[i] == NULL)
continue;
res += lthreads[i]->val;
lthreads[i] = lthreads[i]->next;
if (lthreads[i] == NULL)
n--;
}
}
free(lthreads);
return res;
}Running this new version with the same input as previously described takes less than 2 seconds, achieving a 10x speedup! The explanation for this significant improvement lies in the processor's speculative execution capabilities. In a standard sequential traversal of a linked list, as seen in the first version of the function, the processor cannot 'speculate' on future memory access instructions. This limitation becomes particularly costly with large lists, where each pointer access likely results in a expensive external memory access. In contrast, the alternative implementation, which interleaves list traversals, allows the processor to issue more memory accesses in parallel. This leads to an overall reduction in memory access latency through amortization.
One way to maximize the amount of parallel memory access issued is to add prefetch instructions. Replacing
if (lthreads[i] == NULL)
n--;with
if (lthreads[i])
__builtin_prefetch(lthreads[i]);
else
n--;reduces the execution time further to 1.8 sec.
Back to Valkey
In the first part, we described how we updated the existing I/O threads implementation to increase parallelism and reduce the amount of I/O operations executed by the main thread to a minimum. Indeed, we observed an increase in the number of requests per second, reaching up to 780K SET commands per second. Profiling the execution revealed that Valkey's main thread was spending more than 40% of its time in a single function: lookupKey, whose goal is to locate the command keys in Valkey's main dictionary. This dictionary is implemented as a straightforward chained hash, as shown in the picture below:
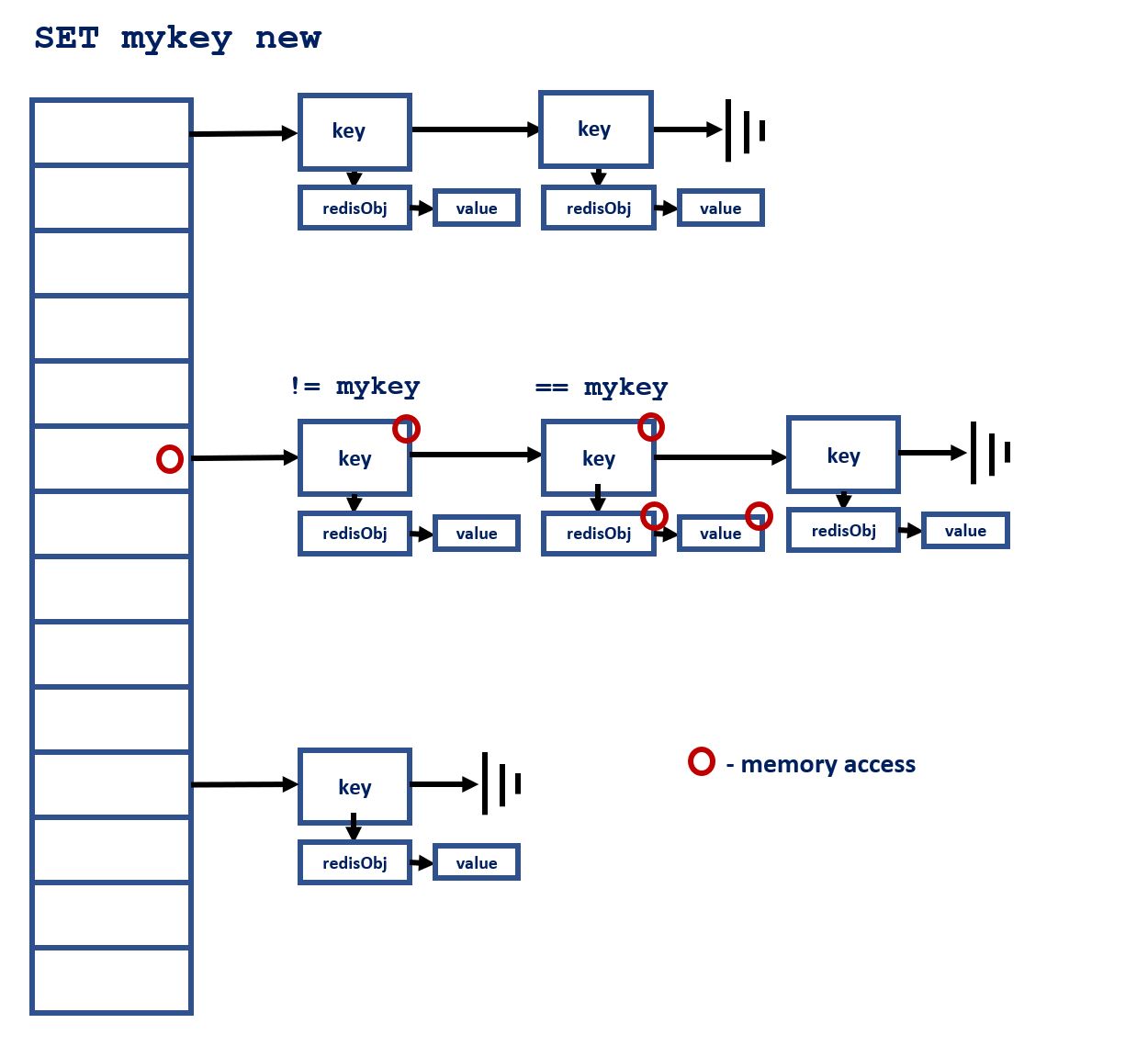 On a large enough set of keys, almost every memory address accessed while searching the dictionary will not be found in any of the processor caches, resulting in costly external memory accesses. Also, similarly as with the linked list from above, since the addresses in the table→dictEntry→...dictEntry→robj sequence are serially dependent, it is not possible to determine the next address to be accessed before the previous address in the chain has been resolved.
On a large enough set of keys, almost every memory address accessed while searching the dictionary will not be found in any of the processor caches, resulting in costly external memory accesses. Also, similarly as with the linked list from above, since the addresses in the table→dictEntry→...dictEntry→robj sequence are serially dependent, it is not possible to determine the next address to be accessed before the previous address in the chain has been resolved.
Batching and interleaving
To overcome this inefficiency, we adopted the following approach. Every time a batch of incoming commands from the I/O threads is ready for execution, Valkey’s main thread efficiently prefetches the memory addresses needed for future lookupKey invocations for the keys involved in the commands before executing the commands. This prefetch phase is achieved by dictPrefetch, which, similarly as with the linked list example from above, interleaves the table→dictEntry→...dictEntry→robj search sequences for all keys. This reduces the time spent on lookupKey by more than 80%. Another issue we had to address was that all the incoming parsed commands from the I/O threads were not present in the L1/L2 caches of the core running Valkey’s main thread. This was also resolved using the same method. All the relevant code can be found in memory_prefetch.c. In total the impact of the memory access amortization on Valkey performance is almost 50% and it increased the requests per second to more than 1.19M rps.
How to reproduce Valkey 8.0 performance numbers
This section will walk you through the process of reproducing our performance results, where we achieved 1.19 million requests per second using Valkey 8.
Hardware Setup
We conducted our tests on an AWS EC2 c7g.4xlarge instance, featuring 16 cores on an ARM-based (aarch64) architecture.
System Configuration
Note: The core assignments used in this guide are examples. Optimal core selection may vary depending on your specific system configuration and workload.
Interrupt affinity - locate the network interface with ifconfig (let's assume it is eth0) and its associated IRQs with
grep eth0 /proc/interrupts | awk '{print $1}' | cut -d : -f 1In our setup, lines 48 to 55 are allocated for eth0 interrupts. Allocate one core per 4 IRQ lines:
for i in {48..51}; do echo 1000 > /proc/irq/$i/smp_affinity; done
for i in {52..55}; do echo 2000 > /proc/irq/$i/smp_affinity; doneServer configuration - launch the Valkey server with these minimal configurations:
./valkey-server --io-threads 9 --save --protected-mode no--save disables dumping to RDB file and --protected-mode no allows connections from external hosts. --io-threads number includes the main thread and the IO threads, meaning that in our case 8 I/O threads are launched in addition to the main thread.
Main thread affinity - pin the main thread to a specific CPU core, avoiding the cores handling IRQs. Here we use core #3:
sudo taskset -cp 3 `pidof valkey-server`Important: We suggest experimenting with different core pinning strategies to find the optimal performance while avoiding conflicts with IRQ-handling cores.
Benchmark Configuration
Run the benchmark from a separate instance using the following parameters:
- Value size: 512 bytes
- Number of keys: 3 million
- Number of clients: 650
- Number of threads: 50 (may vary for optimal results)
./valkey-benchmark -t set -d 512 -r 3000000 -c 650 --threads 50 -h "host-name" -n 100000000000Important: When running the benchmark, it may take a few seconds for the database to get populated and for the performance to stabilize. You can adjust the
-nparameter to ensure the benchmark runs long enough to reach optimal throughput.
Testing and Availability
Valkey 8.0 RC2 is available now for evaluation with I/O threads and memory access amortization.
