
Unlock 1 Million RPS: Experience Triple the Speed with Valkey
Valkey 8.0, set for release in September 2024, will bring major performance enhancements through a variety of improvements including a new multi-threaded architecture. This update aims to significantly boost throughput and reduce latency across various hardware configurations. Read on to learn more about the new innovative I/O threading implementation and its impact on performance and efficiency. This post is the first in a two-part series. The next post will dive into the new prefetch mechanism and its impact on performance.
Our Commitment to performance and efficiency
At AWS, we have hundreds of thousands of customers using Amazon ElastiCache and Amazon MemoryDB. Feedback we continuously hear from end users is that they need better absolute performance and want to squeeze more performance from their clusters.
Our commitment to meeting these performance and efficiency needs led us down a path of improving the multi-threaded performance of our ElastiCache and MemoryDB services, through features we called Enhanced IO and Multiplexing. Today we are excited to dive into how we are sharing our learnings from this performance journey by contributing a major performance improvement to the Valkey project.
Benefits of High Capacity Shards
Valkey's common approach to performance and memory improvement is scaling out by adding more shards to the cluster. However, the availability of more powerful nodes offers additional flexibility in application design. Higher-capacity shards can increase cluster capacity, improve resilience to request surges, and reduce latencies at high percentiles. This approach is particularly beneficial for Valkey users with workloads that don't respond well to horizontal scaling, such as hot keys and large collections that can't be effectively distributed across multiple shards.
Another challenge with horizontal scaling comes from multi-key operations like MGET. These multi-key operations require all involved keys to reside in the same slot, often resulting in users utilizing only a small number of slots, which can significantly restrict the cluster's scalability potential. Larger shards can alleviate these constraints by accommodating more keys and larger collections within a single node.
While larger shards offer these benefits, they come with trade-offs. Full synchronization for very large instances can be risky, and losing a large shard can be more impactful than losing a smaller one. Conversely, managing a cluster with too many small instances can be operationally complex. The optimal configuration depends on the specific workload, requiring a careful balance between scaling out and using larger shards.
Major Upgrade to Valkey Performance
Starting with version 8, Valkey users will benefit from an increase in multi-threaded performance, thanks to a new multi-threading architecture that can boost throughput and reduce latency on a wide range of hardware types.
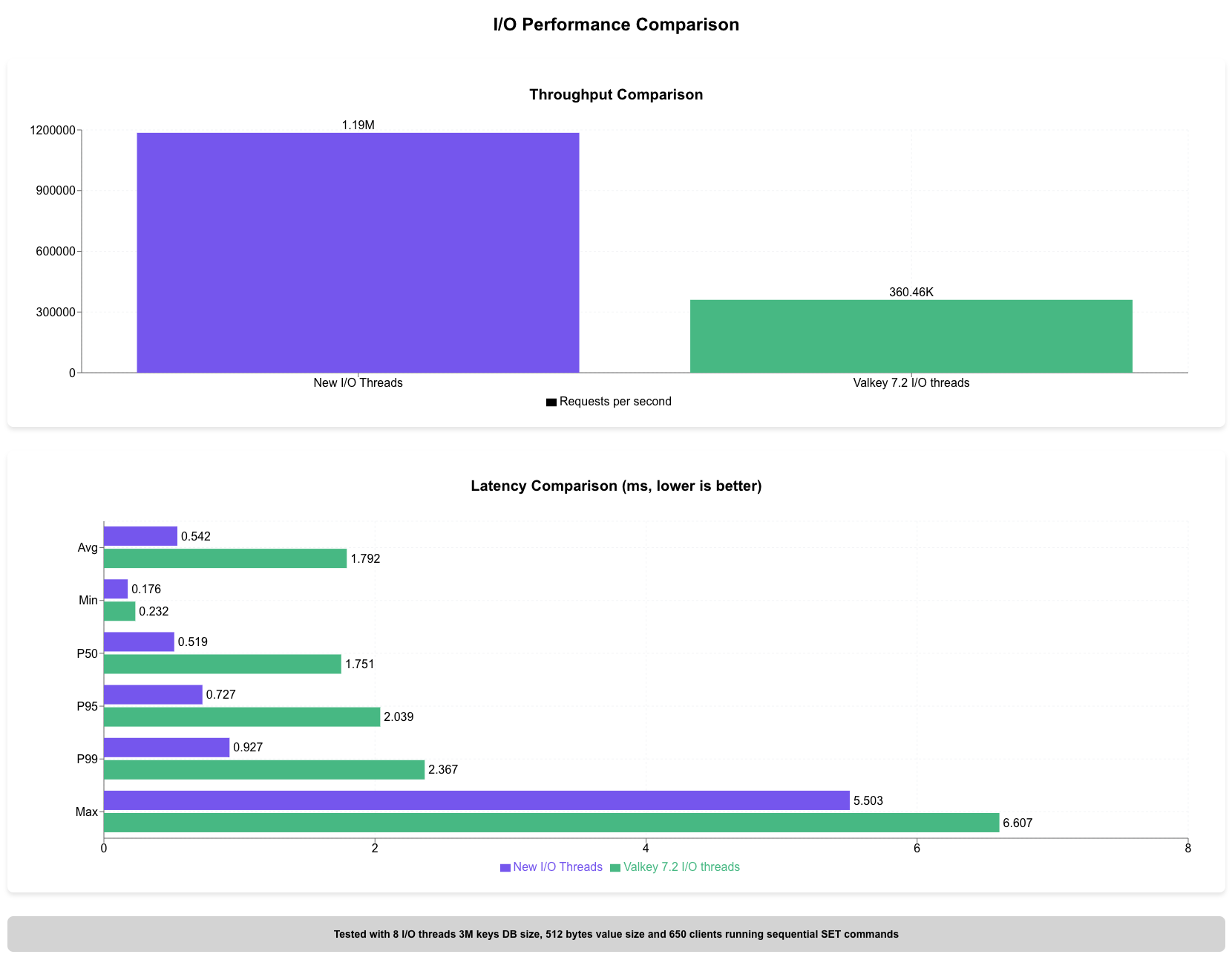
The data demonstrates a substantial performance improvement with the new I/O threads approach. Throughput increased by approximately 230%, rising from 360K to 1.19M requests per second compared to Valkey 7.2 Latency metrics improved across all percentiles, with average latency decreasing by 69.8% from 1.792 ms to 0.542 ms.
Tested with 8 I/O threads, 3M keys DB size, 512 bytes value size, and 650 clients running sequential SET commands using AWS EC2 C7g.16xlarge instance. Please note that these numbers include the Prefetch change that will be described in the next blog post
Performance Without Compromising Simplicity
Valkey strives to stay simple by executing as much code in a single thread as possible. This ensures an API that can continuously evolve without the need to use complex synchronization and avoid race conditions. Our new multi-threading approach is designed based on this long-standing architectural principle that we believe is the right architecture for Valkey. It utilizes a minimal number of synchronization mechanisms and keeps Valkey command execution single-threaded, simple, and primed for future enhancements.
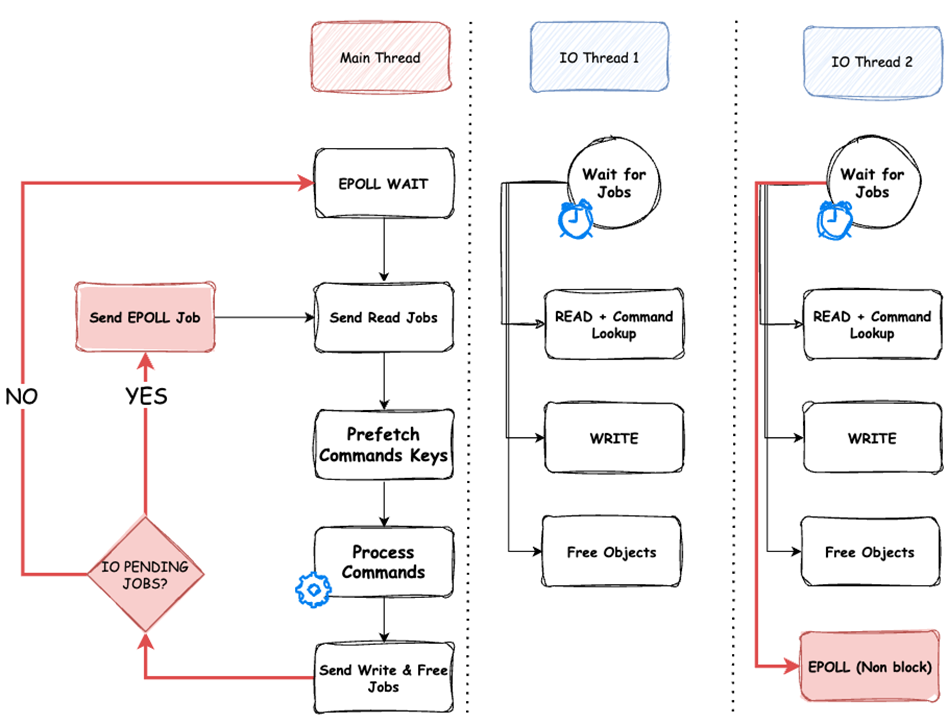
High Level Design
The above diagram depicts the high-level design of I/O threading in Valkey 8. I/O threads are worker threads that receive jobs to execute from the main thread. A job can involve reading and parsing a command from a client, writing responses back to the client, polling for I/O events on TCP connections, or deallocating memory. While I/O threads are busy handling I/O, the main thread is able to spend more time executing commands.
The main thread orchestrates all the jobs spawned to the I/O threads, ensuring that no race conditions occur. The number of active I/O threads can be adjusted by the main thread based on the current load to ensure efficient utilization of the underlying hardware. Despite the dynamic nature of I/O threads, the main thread maintains thread affinity, ensuring that, when possible the same I/O thread will handle I/O for the same client to improve memory access locality.
Socket polling system calls, such as epoll_wait, are expensive procedures.
When executed solely by the main thread, epoll_wait consumes more than 20 percent of the time.
Therefore, we decided to offload epoll_wait execution to the I/O threads in the following way: to avoid race conditions, at any given time, at most one thread, either an io_thread or the main thread, executes epoll_wait.
I/O threads never sleep on epoll, and whenever there are pending I/O operations or commands to be executed, epoll_wait calls are scheduled to the I/O threads by the main thread.
In all other cases, the main thread executes the epoll_wait with the waiting time as in the original Valkey implementation
In addition, before executing commands, the main thread performs a new procedure, prefetch-commands-keys, which aims to reduce the number of external memory accesses needed when executing the commands on the main dictionary. A detailed explanation of the technique used in that procedure will be described in our next blog
Testing and Availability
The enhanced performance will be available for testing in the first release candidate of Valkey, available today.
