
Introducing Bloom Filters for Valkey
The Valkey project is introducing Bloom Filters as a new data type via valkey-bloom (BSD-3 licensed), an official Valkey Module which is compatible with Valkey versions >= 8.0. Bloom filters provide efficient, large-scale membership testing, improving performance and offering significant memory savings for high-volume applications.
As an example, to handle advertisement deduplication workloads and answer the question, "Has this customer seen this ad before?", Valkey developers could use the SET data type.
This is done by adding the customer IDs (of those who viewed an ad) into a SET object representing a particular advertisement. However, the problem with this approach is high memory usage since every item in the set is allocated.
This article demonstrates how using the bloom filter data type from valkey-bloom can achieve significant memory savings, more than 93% in our example workload, while exploring its implementation, technical details, and practical recommendations.
Introduction
Bloom filters are a space efficient probabilistic data structure that supports adding elements and checking whether elements were previously added. False positives are possible, where a filter incorrectly indicates that an element exists even though it was not added. However, Bloom Filters guarantee that false negatives do not occur, meaning that an element that was added successfully will never be reported as not existing.
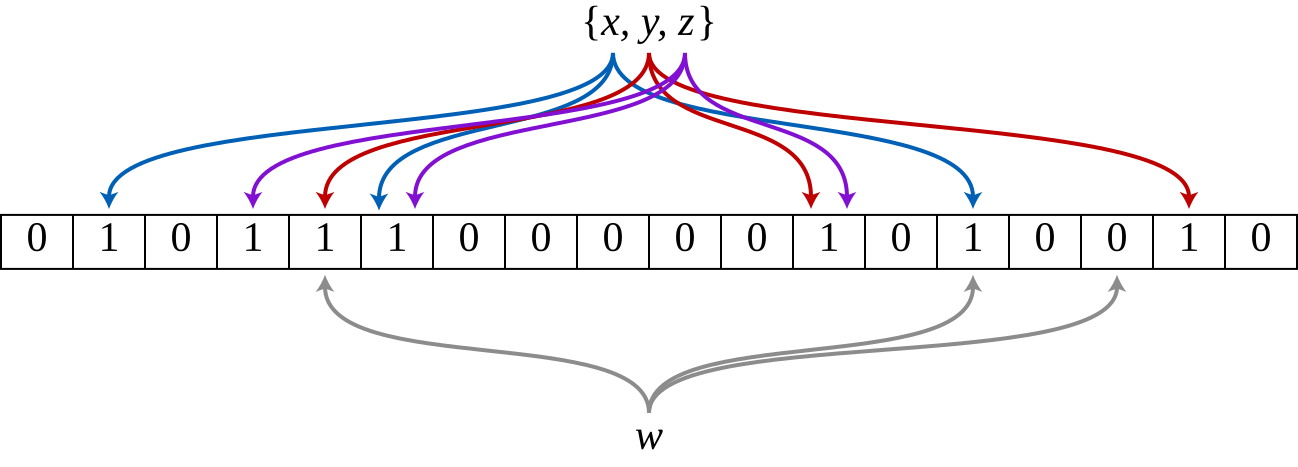 Image taken from source
Image taken from source
When adding an item to a bloom filter, K different hash functions compute K corresponding bits from the bit vector, which are then set to 1. Checking existence involves the same hash functions - if any bit is 0, the item is definitely absent; if all bits are 1, the item likely exists (with a defined false positive probability). This bit-based approach, rather than full item allocation, makes bloom filters very space efficient with the trade off being potential false positives.
Valkey-Bloom introduces bloom filters as a new data type to Valkey, providing both scalable and non-scalable variants. It is API compatible with the bloom filter command syntax of the official Valkey client libraries including valkey-py, valkey-java, valkey-go (as well as the equivalent Redis libraries).
Data type overview
The "Bloom Object" is the main bloom data type structure. This is what gets created with any bloom filter creation command and this structure can act either as a "scaling bloom filter" or "non scaling bloom filter" depending on the user configuration. It consists of a vector of "Sub Filters" with length >= 1 in case of scaling and only 1 in case of non scaling.
The "Sub Filter" is an inner structure which is created and used within the "Bloom Object". It tracks the capacity, number of items added, and an instance of a Bloom Filter (of the specified properties).
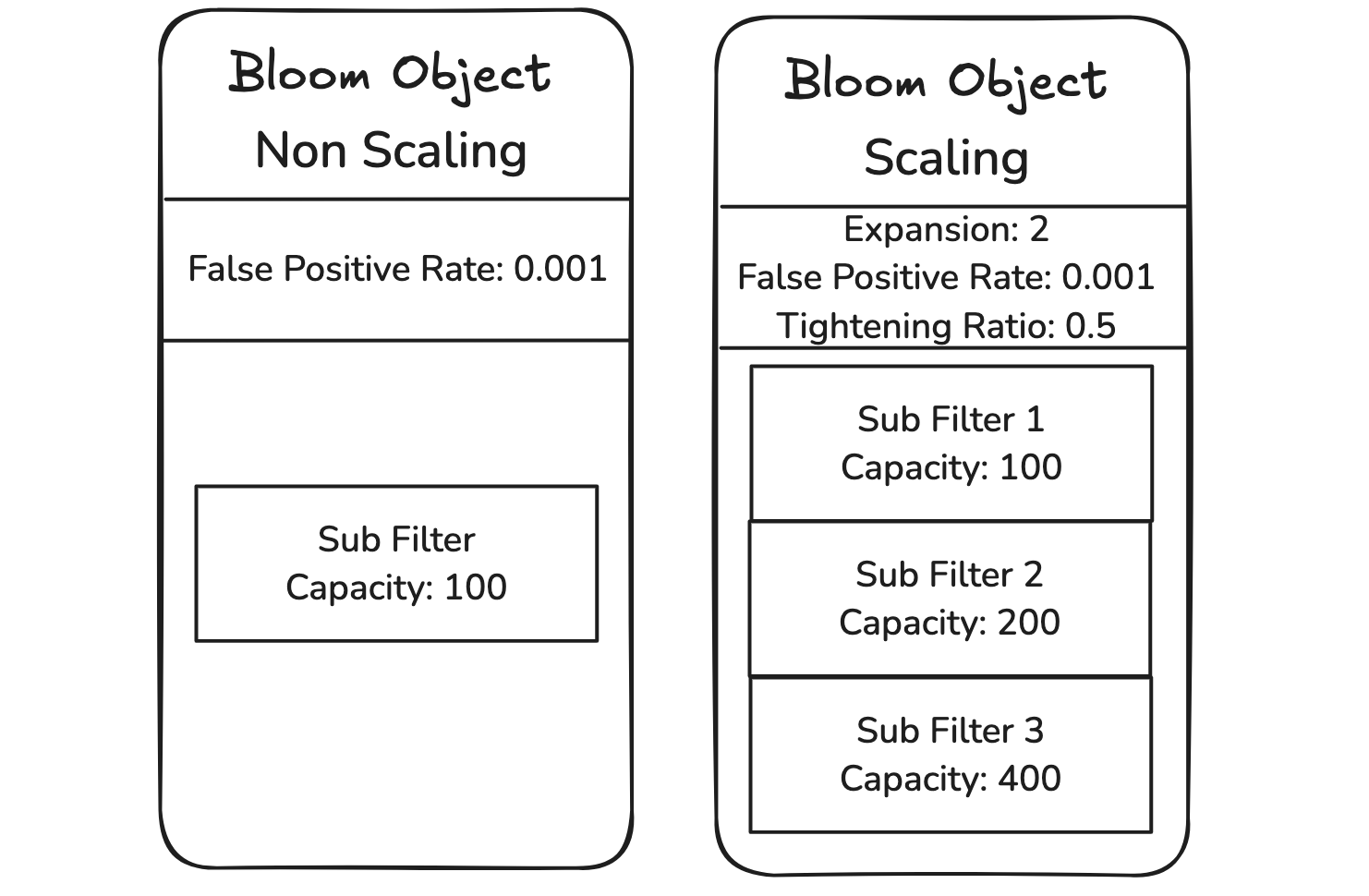
Non Scaling
When non-scaling filters reach their capacity, if a user tries to add a new/unique item, an error is returned.
You can create a non scaling bloom filter using BF.RESERVE or BF.INSERT commands.
Example:
BF.RESERVE <filter-name> <error-rate> <capacity> NONSCALINGScaling
When scaling filters reach their capacity, if a user adds an item to the bloom filter, a new sub filter is created and added to the vector of sub filters.
This new bloom sub filter will have a larger capacity (previous_bloomfilter_capacity * expansion_rate of the bloom filter).
When checking whether an item exists on a scaled out bloom filter (BF.EXISTS/BF.MEXISTS), we look through each filter (from oldest to newest) in the sub filter vector and perform a check operation on each one.
Similarly, to add a new item to the bloom filter, we check through all the filters to see if the item already exists and the item is added to the current filter if it does not exist.
Any default creation as a result of BF.ADD, BF.MADD, BF.INSERT will be a scalable bloom filter.
Common Bloom filter properties
Capacity - The number of unique items that can be added before a bloom filter scales out occurs (in case of scalable bloom filters) or before any command which inserts a new item will return an error (in case of non scalable bloom filters).
False Positive Rate (FP) - The rate that controls the probability of item add/exists operations being false positives. Example: 0.001 means 1 in every 1000 operations can be a false positive.
Use cases / Memory Savings
In this example, we are simulating a very common use case of bloom filters: Advertisement Deduplication. Applications can utilize bloom filters to track whether an advertisement / promotion has already been shown to a customer and use this to prevent showing it again to the customer.
Let us assume we have 500 unique advertisements and our service has 5M customers. Both advertisements and customers are identified by a UUID (36 characters).
Without bloom filters, applications could use the SET Valkey data type such that they have a unique SET for every advertisement.
Then, they can use the SADD command to track every customer who has already seen this particular advertisement by adding them to the set.
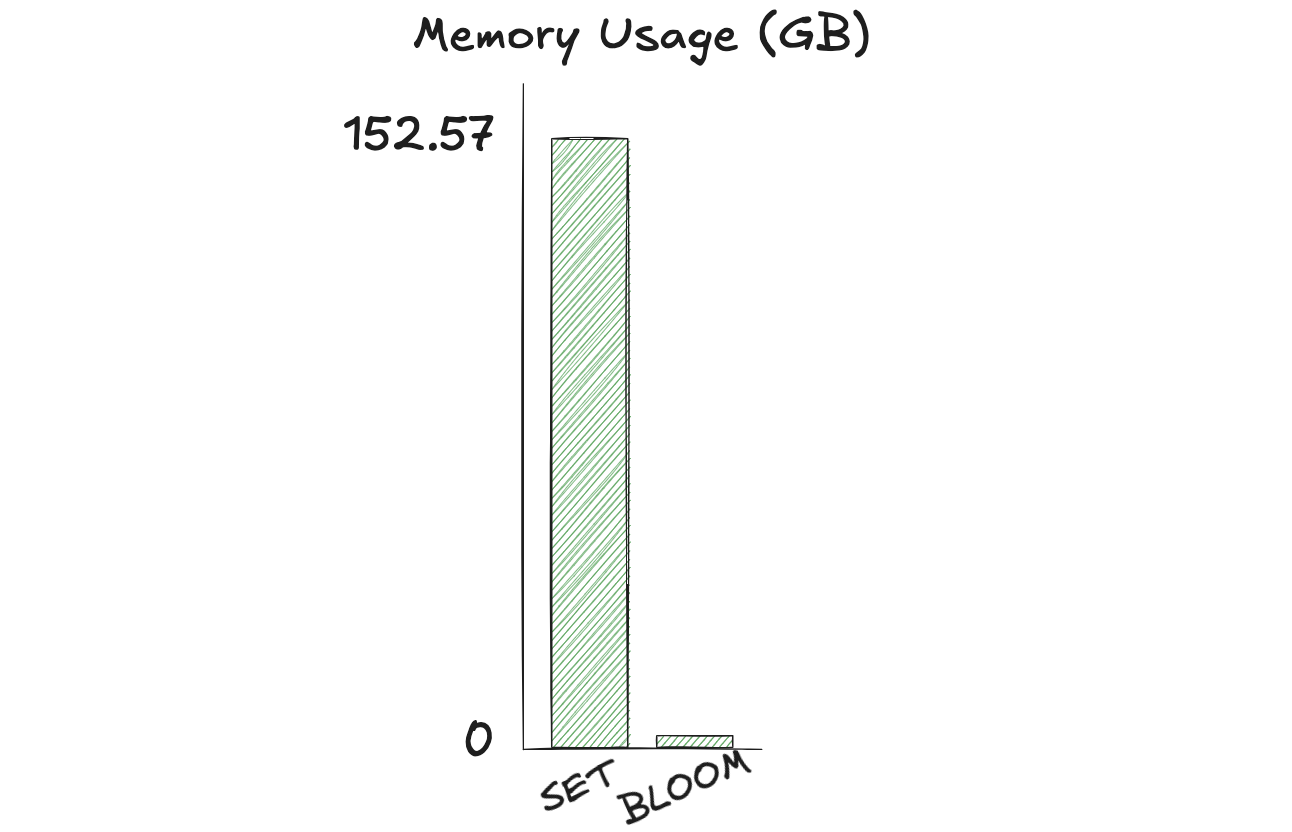
To check if a customer has seen the ad, the SISMEMBER or SMISMEMBER command can be used. This means we have 500 sets, each with 5M members. This will require ~152.57 GB of used_memory on a Valkey 8.0 server.
With bloom filters, applications can create a unique bloom filter for every advertisement with the BF.RESERVE or BF.INSERT command.
Here, they can specify the exact capacity they require: 5M - which means 5M items can be added to the bloom filter. For every customer that the advertisement is shown to, the application can add the UUID of the customer onto the specific filter.
To check if a customer has seen the ad, the BF.EXISTS or BF.MEXISTS command can be used. So, we have 500 bloom filters, each with a capacity of 5M.
This will require variable memory depending on the false positive rate. In all cases (even stricter false positive rates), we can see there is a significant memory optimization compared to using the SET data type.
| Number of Bloom Filters | Capacity | FP Rate | FP Rate Description | Total Used Memory (GB) | Memory Saved % compared to SETS |
|---|---|---|---|---|---|
| 500 | 5000000 | 0.01 | One in every 100 | 2.9 | 98.08% |
| 500 | 5000000 | 0.001 | One in every 1K | 4.9 | 96.80% |
| 500 | 5000000 | 0.00001 | One in every 100K | 7.8 | 94.88% |
| 500 | 5000000 | 0.0000002 | One in every 5M | 9.8 | 93.60% |
In this example, we are able to benefit from 93% - 98% savings in memory usage when using Bloom Filters compared to the SET data type. Depending on your workload, you can expect similar results.
Large Bloom Filters and Recommendations
To improve server performance during serialization and deserialization of bloom filters, we have added validation on the memory usage per object.
The default memory usage limit of a bloom filter is defined by the BF.BLOOM-MEMORY-USAGE-LIMIT configuration which has a default value of 128 MB.
However, the value can be tuned using the configuration above.
The implication of the memory limit is that operations involving bloom filter creations or scaling out, that result in a bloom filter with overall memory usage over the limit, will return an error. Example:
127.0.0.1:6379> BF.ADD ad1_filter user1
(error) ERR operation exceeds bloom object memory limitThis poses an issue to users where their scalable bloom filters can reach the memory limit after some number of days of data population and it starts failing scale outs during the insertion of unique items.
As a solution, to help users understand at what capacity their bloom filter will hit the memory limit, valkey-bloom has two options. These are useful to check beforehand to ensure that your bloom filter will not fail scale outs or creations later on as part of your workload.
- Perform a memory check prior to bloom filter creation
We can use the VALIDATESCALETO option of the BF.INSERT command to perform a validation whether the filter is within the memory limit.
If it is not within the limits, the command will return an error. In the example below, we see that filter1 cannot scale out and reach the capacity of 26214301 due to the memory limit. However, it can scale out and reach a capacity of 26214300.
127.0.0.1:6379> BF.INSERT filter1 VALIDATESCALETO 26214301
(error) ERR provided VALIDATESCALETO causes bloom object to exceed memory limit
127.0.0.1:6379> BF.INSERT filter1 VALIDATESCALETO 26214300 ITEMS item1
1) (integer) 1- Check the maximum capacity that an existing scalable bloom filter can expand to
We can use the BF.INFO command to find out the maximum capacity that the scalable bloom filter can expand to hold. In this case, we can see the filter can hold 26214300 items (after scaling out until the memory limit).
127.0.0.1:6379> BF.INFO filter1 MAXSCALEDCAPACITY
(integer) 26214300To get an idea of what the memory usage looks like for the max capacity of an individual non scaling filter, we have a table below. With a 128MB limit and default false positive rate, we can create a bloom filter with 112M as the capacity. With a 512MB limit, a bloom filter can hold 448M items.
| Non Scaling Filter - Capacity | FP Rate | Memory Usage (MB) | Notes |
|---|---|---|---|
| 112M | 0.01 | ~128 | Default FP Rate and Default Memory Limit |
| 74M | 0.001 | ~128 | Custom FP Rate and Default Memory Limit |
| 448M | 0.01 | ~512 | Default FP Rate and Custom Memory Limit |
| 298M | 0.001 | ~512 | Custom FP Rate and Custom Memory Limit |
Performance
The bloom commands which involve adding items or checking the existence of items have a time complexity of O(N * K) where N is the number of elements being inserted and K is the number of hash functions used by the bloom filter.
This means that both BF.ADD and BF.EXISTS are both O(K) as they only operate on one item.
In scalable bloom filters, we increase the number of hash function based checks during add/exists operations with each scale out; Each sub filter requires at least one hash function and this number increases as the false positive rate becomes stricter with scale outs due to the tightening ratio. For this reason, it is recommended that users choose a capacity and expansion rate after evaluating the use case / workload to avoid several scale outs and reduce the number of checks.
Example: For a bloom filter to achieve an overall capacity of 10M with a starting capacity of 100K and expansion rate of 1, it will require 100 sub filters (after 99 scale outs). Instead, with the same starting capacity of 100K and expansion rate of 2, a bloom filter can achieve an overall capacity of ~12.7M with just 7 sub filters. Alternatively, with the same expansion rate of 1 and starting capacity of 1M, a bloom filter can achieve an overall capacity of 10M with 10 sub filters. Both approaches significantly reduce the number of checks per item add / exists operation.
The other bloom filter commands are O(1) time complexity: BF.CARD, BF.INFO, BF.RESERVE, and BF.INSERT (when no items are provided).
Conclusion
valkey-bloom offers an efficient solution for high-volume membership testing through bloom filters, providing significant memory usage savings compared to traditional data types. This enhances Valkey's capability to handle various workloads including large-scale advertisement / event deduplication, fraud detection, and reducing disk / backend lookups more efficiently.
To learn more about valkey-bloom, you can read about the Bloom Filters data type and follow the quick start guide to try it yourself. Additionally, to use valkey-bloom on Docker (along with other official modules), you can check out the Valkey Extensions Docker Image.
Thank you to all those who helped develop the module:
- Karthik Subbarao (KarthikSubbarao)
- Cameron Zack (zackcam)
- Vanessa Tang (YueTang-Vanessa)
- Nihal Mehta (nnmehta)
- wuranxx (wuranxx)

{kind=link}