
Introducing Hash Field Expirations
One of the great strengths of Valkey has always been its built-in ability to expire keys. This simple but powerful mechanism lets developers keep their datasets fresh, automatically clear caches, or enforce session lifetimes without additional logic. But there has always been one limitation: expiration worked at the level of whole keys. If you stored multiple fields in a hash, you could set a TTL for the hash itself, but you couldn’t say “this field should live for 10 seconds while another field should stick around for 10 minutes.”
That limitation forced developers into awkward choices.
Imagine you’re running a feature flag system. You want to store all of a customer’s feature toggles inside one hash:
-
Some flags are short-lived experiments, meant to turn off automatically after a few seconds or minutes.
-
Others are long-term rollouts, where the toggle might remain valid for days or weeks.
If you only had key-level expirations, you were forced to compromise. You could put all flags for a customer into a single hash, but then they would all share one expiration time. Or, you could store each flag in its own key so that each could expire independently — but this would explode the number of keys your system has to manage, hurting memory efficiency and increasing overhead for operations.
The inability to set different TTLs per field meant developers either built complex cleanup processes outside of Valkey, or gave up flexibility in how expirations were handled.
Finding the Right Expiration Model
At first glance, adding field expirations might sound like a simple matter of storing timestamps per field. In order to understand the problem, it’s important to understand how expiration is normally handled in Valkey today.
Valkey uses two complementary mechanisms to reclaim expired keys:
-
Lazy expiration: A key is deleted only when accessed. If you try to read or write an expired key, Valkey notices it has passed its TTL and deletes it immediately. This is cheap, but untouched keys would linger indefinitely and waste memory.
-
Active expiration: A background cron job runs 10 times per second, sampling a small set of keys with expiration. Expired keys are deleted until a time budget is reached, ensuring memory is reclaimed proactively without introducing latency spikes.
For hash fields, we made a key design choice: we did not implement lazy expiration.
Adding expiration checks to every HGET, HSET, or HDEL would have complicated the hot path of hash commands and risked performance regressions.
Instead, we extended the active expiration job so that it can now also scan field-level expiration buckets, alongside top-level keys.
This approach keeps expiration logic unified, predictable, and free from new latency cliffs. But it also introduced a challenge: how do we efficiently track and clean up expired fields inside hashes that may contain thousands (or millions) of entries, when only a small subset are volatile — and an even smaller fraction are expired at any given time? The challenge is balancing three conflicting goals:
-
Keep memory usage small. Hashes can grow to millions of fields, so metadata overhead must be minimal.
-
Maintain fast lookups and updates. Most hash commands run in
O(1)time, and expiration tracking can’t change that. -
Reclaim memory efficiently. The active expiration job is time-bounded, so we need to minimize wasted CPU cycles spent scanning unexpired fields.
Approaches Considered
"We explored several ways to solve this problem:
1. Secondary hashtable per field expiration
This seemed simple: build a secondary hashtable in each Hash object which maps only volatile fields.
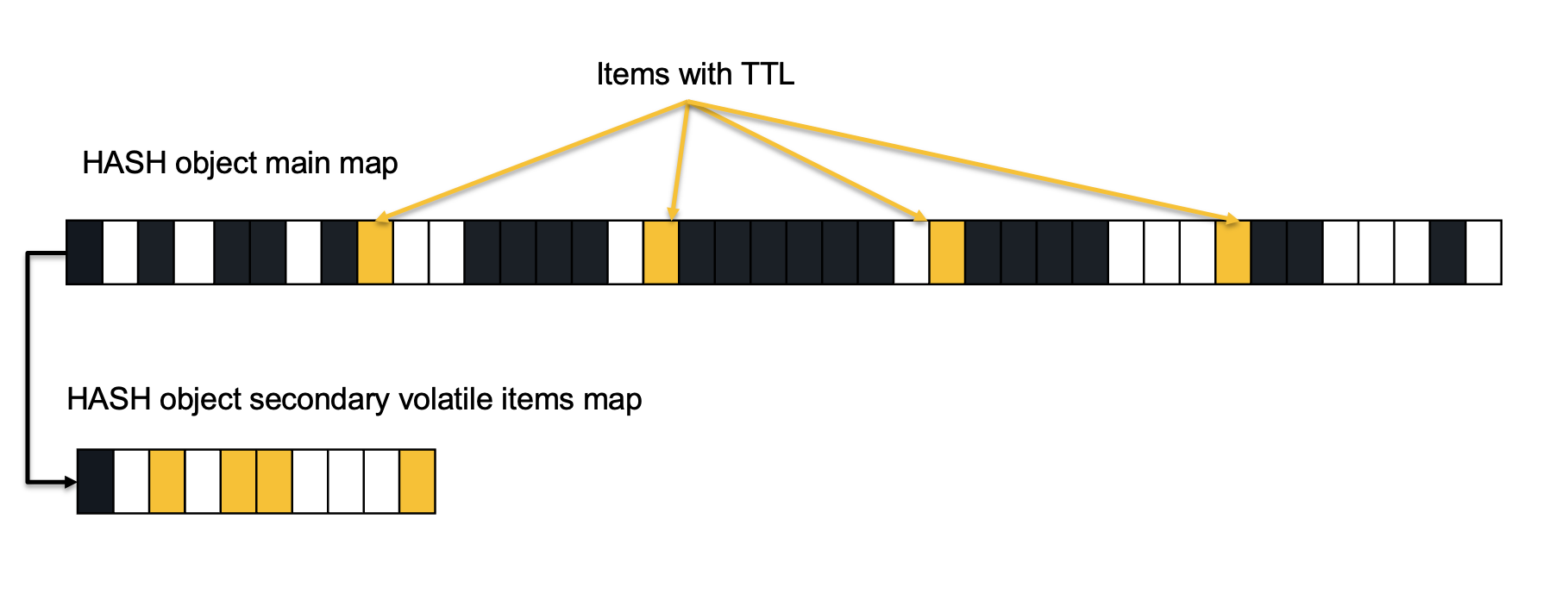
This is actually the way volatile generic keys are being tracked. Per each database, Valkey manage a secondary map mapping volatile keys. During active expiration process the existing job scan the secondary map and each key found to pass it's assigned TTL is expired and it's memory is reclaimed. The problem with this design option is the potential inefficiency introduced while scanning many items which should not expire.
2. Radix Tree-based index
Using a radix tree to hold field names plus expirations provides sorted access for free.
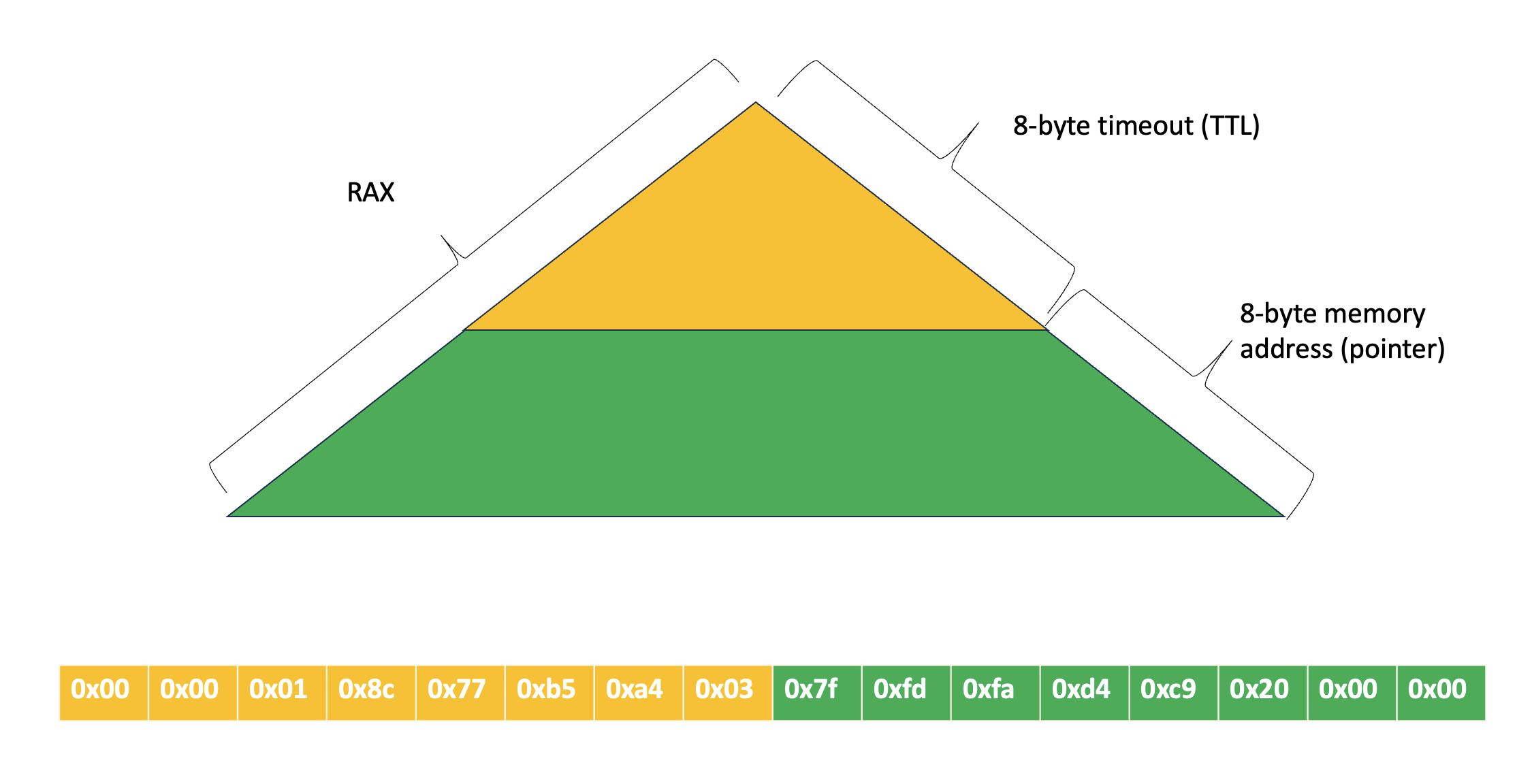
This is also not a new concept in Valkey. In fact this exact structure is being used to manage client connections blocked on key operations
like BLPOP and XREAD.
But the memory overhead per node was high. During experiments we measured more than 54 bytes overhead per each hash field when using this type of index.
3. Global sorted structure
We wanted to have the ability to efficiently scan over fields which are already expired. A good way to achieve this is by using a sorted index. Using a radix tree was possible, but the memory overhead was high. Instead we could use a more lightweight data structure like a skip list, which memory consumption is more bounded and is not governed by the data atrophy.
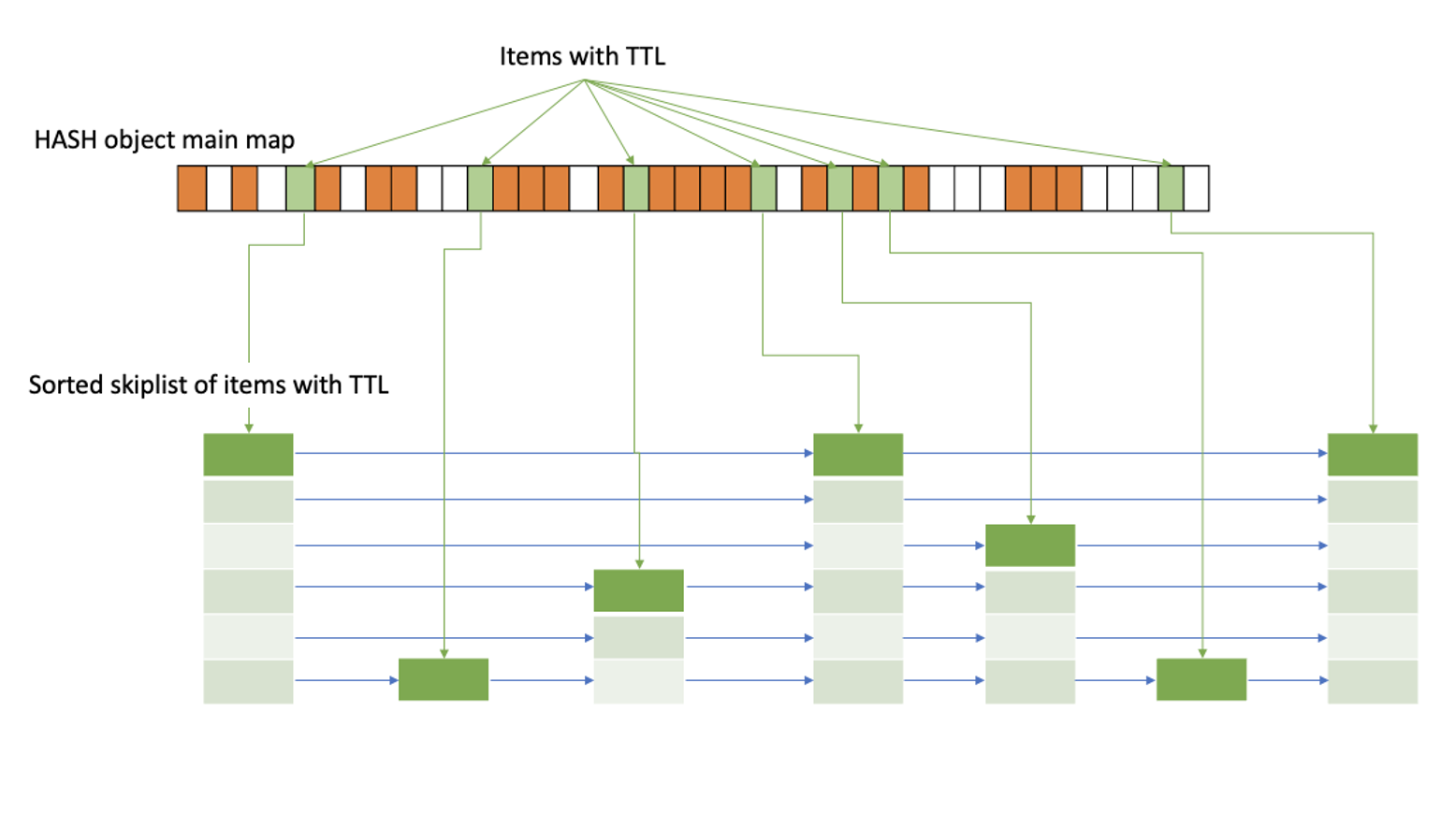
However, This would give O(log N) access to the index which did not work well with our target to keep hash operations constant time complexity.
Coarse Buckets with Adaptive Encoding
Instead of tracking every field’s expiration individually, we designed a coarse bucket system. Each field’s timestamp is mapped into a time bucket, represented by a shared “end timestamp.”
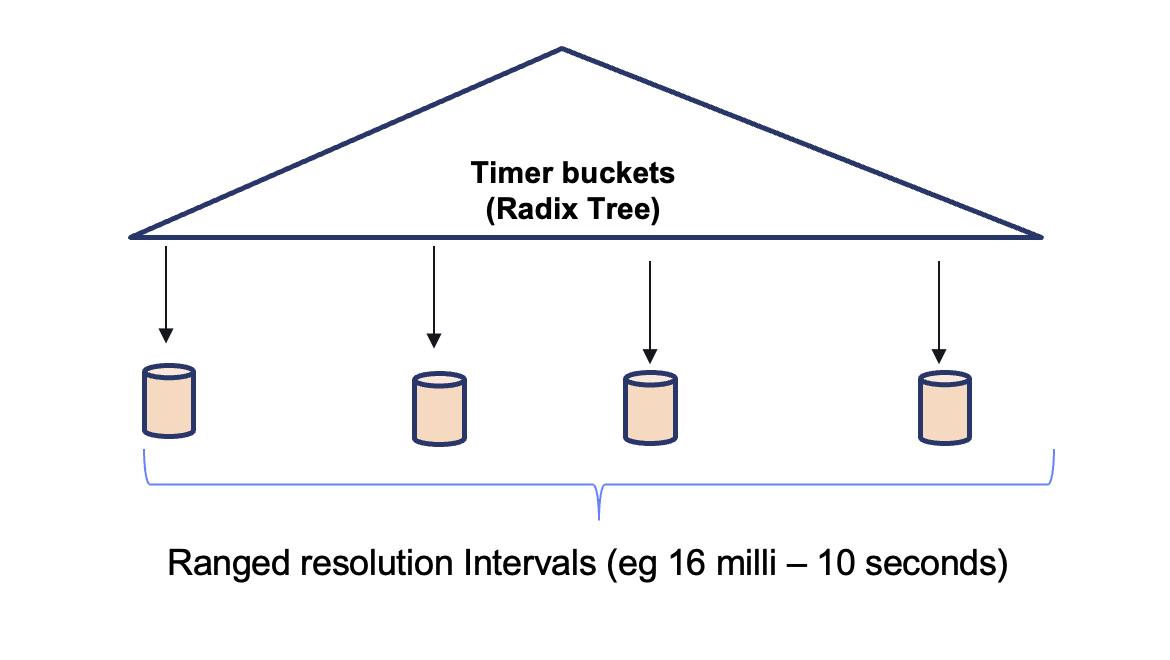
This solution introduces a semi-sorted data structure which we named 'vset' (stands for "volatile set"). The volatile set manages buckets in different time window resolutions and adaptive encodings. Buckets can split if too many expirations cluster in one interval. This adaptability keeps the number of buckets small while ensuring they’re fine-grained enough for efficient cleanup.
When a new field with TTL is added, the volatile set either places it into an existing bucket or creates a new one. If a bucket grows too large, it is narrowed into smaller time windows to keep expiration scans efficient. For example: scanning 1,000 items in a single 10-second bucket may result in mostly misses, while spreading them across 10 smaller buckets avoids wasted work. Why not always use a very small time window (e.g few milliseconds) for each bucket? The reason is memory. Recall that the buckets are managed in a Radix-Tree which introduces a high overhead per each item. When many buckets are used, the memory overhead can be high and we might end up with the same memory overhead introduced by using a Radix-Tree index.
The volatile set also uses different bucket encoding based on the number of items in the bucket. A bucket with only a single element would require just a single pointer size of bytes. A bucket of small amount of items would be encoded as a vector of item pointers, and when the bucket contains many items we will use the Valkey hashtable structure to map the relevant items. This way, we are leveraging existing data structures which are highly optimized for modern CPUs.
A hash object that contains volatile fields now also carries a secondary volatile set index. At the database level, we maintain a global map of hashes with volatile fields. The active expiration cron job scans both regular keys and these hashes, but only iterates over volatile set buckets whose end time has passed. This ensures that CPU time is spent only on fields that are truly ready to expire.
Benchmarking our solution
Validating the new design meant benchmarking across several dimensions: memory overhead, command performance, and expiration efficiency.
Memory Overhead
We first measured the per-field memory overhead when setting TTLs. The raw expiration time itself requires a constant 8 bytes (though this could be reduced in the future by storing only a delta relative to a reference timestamp, such as server start time). On top of that, extra memory is needed for tracking within the volatile set.
The actual overhead depends on both how many fields have expirations and how spread out their expiration times are. This is because the bucket encoding chosen by the volatile set adapts to the data distribution. In practice, the overhead ranged between 16 and 29 bytes per field.
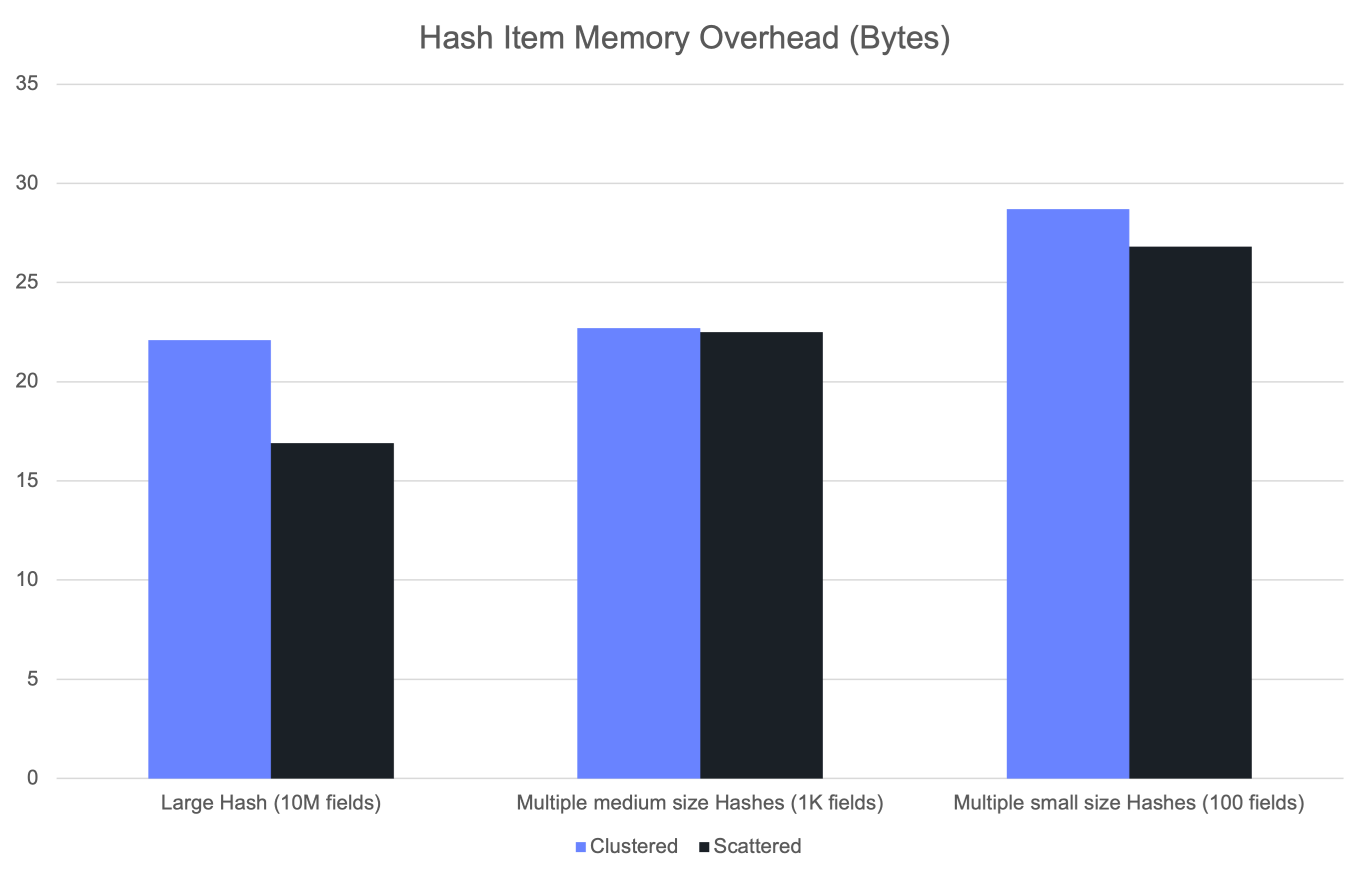
The higher end of this range primarily affects small hashes, where compact encodings like listpack are avoided when volatile fields are present.
Command Performance
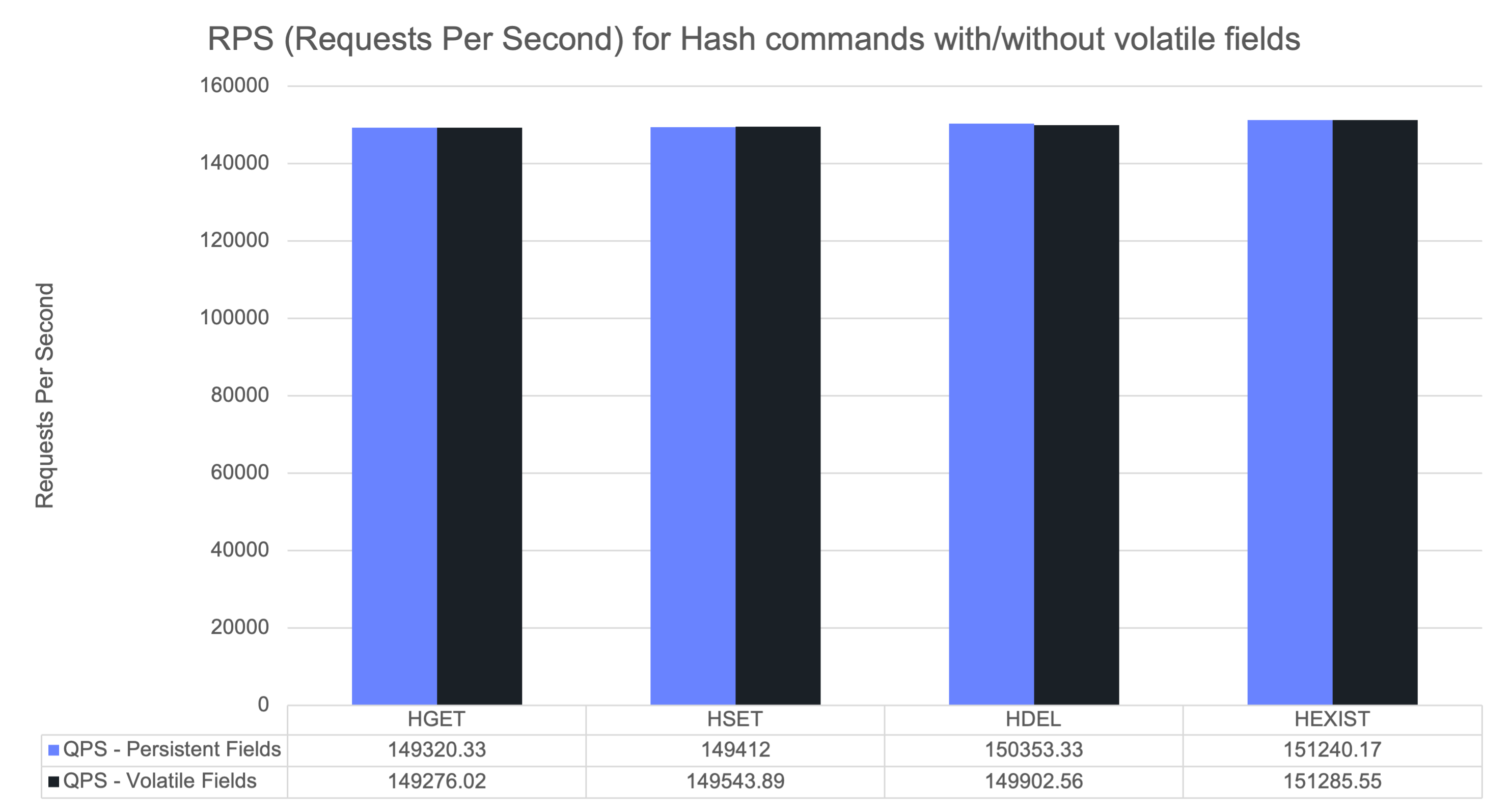
Next, we benchmarked common hash commands both with and without field expirations. The results showed no measurable performance regression and throughput remained stable when expirations were added.
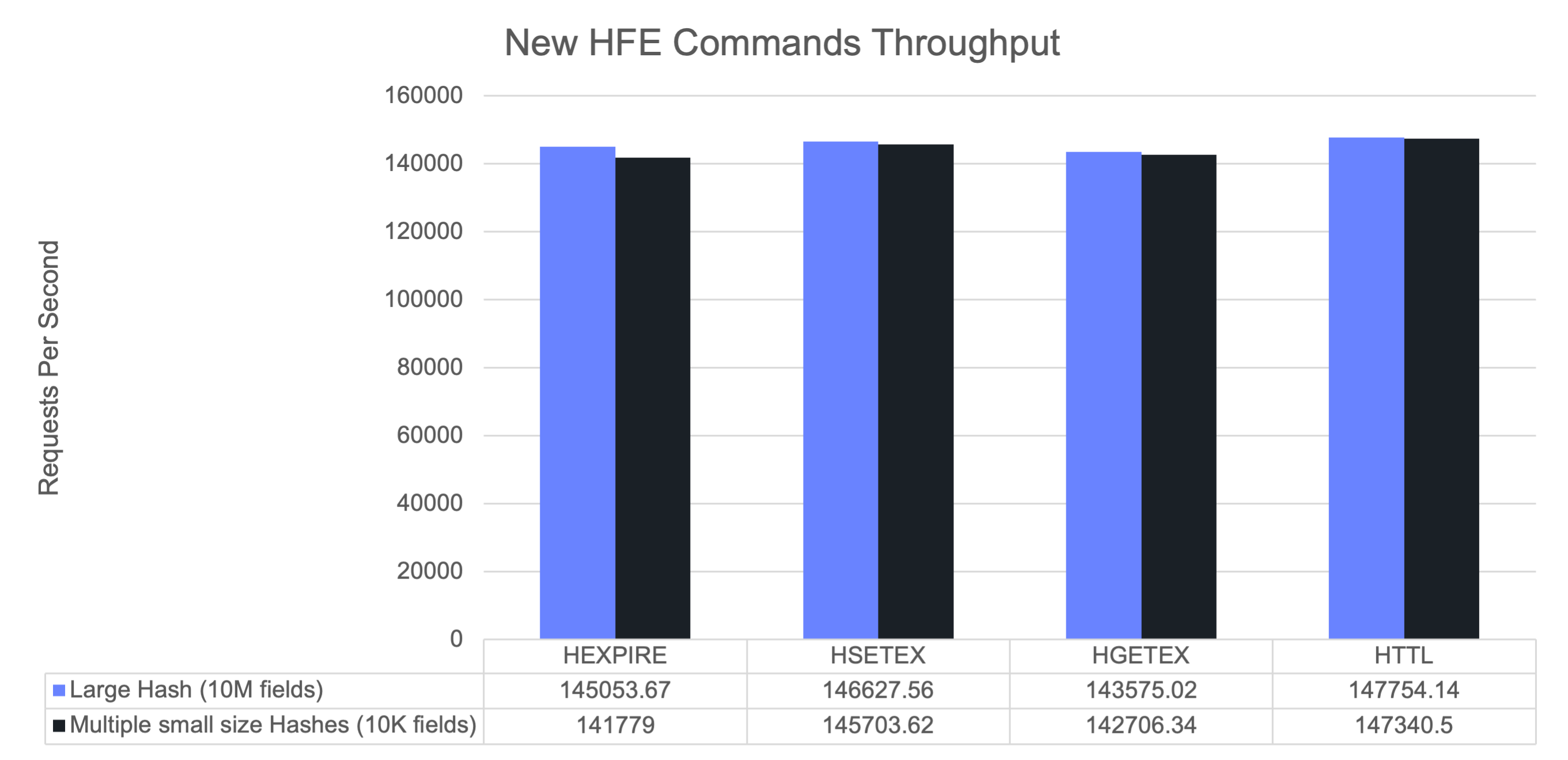
We also benchmarked the new expiration-aware commands (e.g., HSETEX), confirming that their performance is on par with traditional hash operations.
Active Expiration Efficiency
The design goal of the volatile set was to enable efficient background deletion of expired fields.
To test this, we preloaded 10 million fields with TTLs.
We distributed these fields across varying numbers of hash objects to see how object size influences expiration.
During the load phase, we disabled the expiration job using the DEBUG, then re-enabled it once all fields had expired.
The following chart shows the time it took the expiration cron job to complete the full deletion of all the 10M fields.
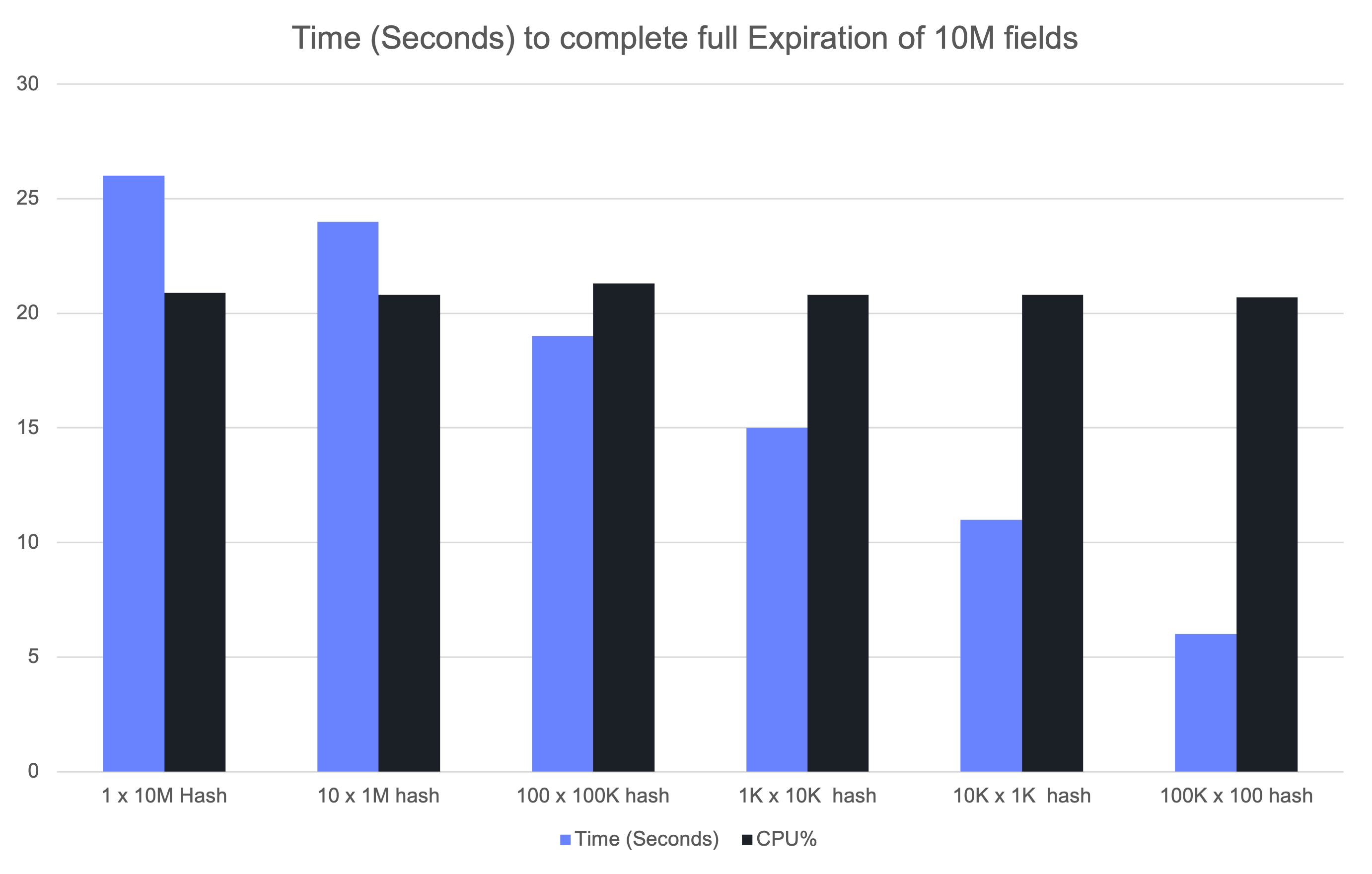
The results revealed that expiration time depends not just on the number of fields, but also on how they are distributed across objects. Smaller hashes tend to fit into CPU caches, so random field deletions remain cache-friendly. Very large hashes, however, cannot fit entirely in cache, which means more expensive memory lookups during expiration.
Another important factor is CPU utilization. The active expiration job is deliberately CPU-bounded and designed to use no more than ~25% of available CPU time (unless configured to work more aggressively), preventing it from overwhelming the system. The chart above shows that average CPU usage was consistently kept under this cap, even when expiring millions of fields, ensuring predictable tail latency.
We also simulated a more realistic scenario: expiring data during continuous ingestion.
Using the 'valkey-benchmark' executing the new HSETEX command, we continuously
inserted 10 million fields with 10-second TTLs, while the active expiration job ran in the background.
This setup maintained a constant pool of fields at different stages of their lifecycle — some fresh, some nearing expiration, some ready to be reclaimed. We then tracked memory usage over a 5-minute period.
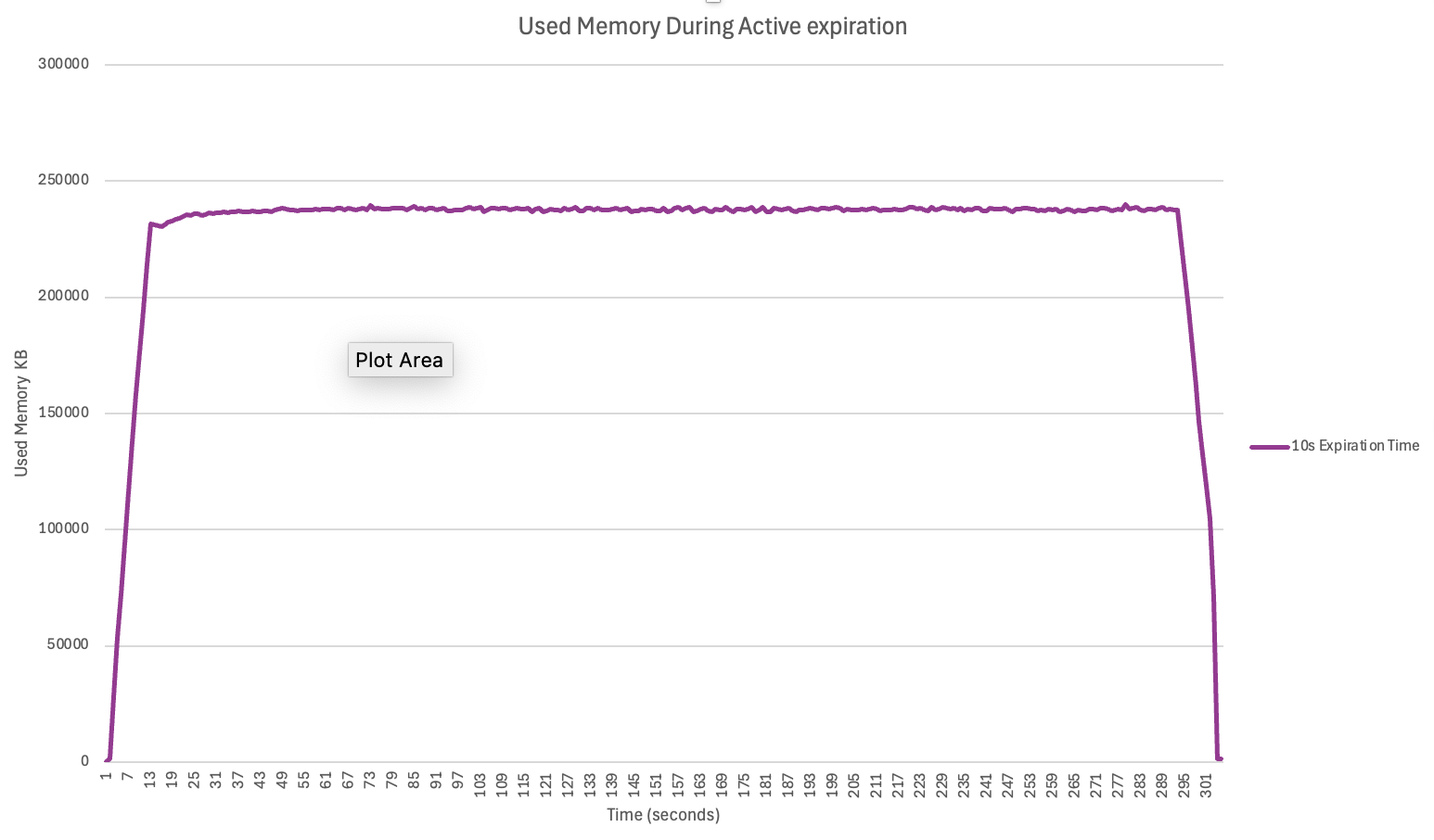
The results aligned with our theoretical expectation:
Memory = (Injection Throughput) x (AVG TTL) x (AVG Item memory)In our experiment:
-
Injection rate: 300K commands/sec
-
Average TTL: 10 seconds
-
Base item size: ~61 bytes
-
Additional expiration overhead: ~19 bytes
This yields an expected memory footprint of ~230MB:
300K × 10 × 80B = 230MBThe observed memory matched this estimate closely, demonstrating that the active expiration mechanism is able to keep up with load and prevent memory from spiking unexpectedly.
Benchmark Takeaways
The benchmarks demonstrate that field-level expirations can be added to Valkey without compromising memory efficiency, or latency. The memory overhead remains modest and predictable, command throughput is unaffected, and the shared active expiration job efficiently reclaims memory even under heavy ingestion workloads. Together, these results validate that the coarse-bucket design with adaptive encoding delivers the right balance of efficiency, scalability, and correctness, while preserving Valkey’s reputation for high performance and low latency.
Using Hash Field Expiration in Valkey
Valkey 9.0 introduces a new API for hash field expirations, fully compatible with the Redis 8.0 API. Any existing client library supporting this API can be used. In this example, we will use the latest valkey-glide 2.1.0 release, which also supports the new hash field expiration commands.
Let's start with a simple example.
First, we create a client connecting to a local Valkey server:
from glide_sync import GlideClientConfiguration, NodeAddress, GlideClient
addresses = [NodeAddress("localhost", 6379)]
config = GlideClientConfiguration(addresses, request_timeout=500) # 500ms timeout
client = GlideClient.create(config)Next, let's create a new hash object to store some random user data:
client.hset("User1", {"name": "Ran", "age": 'old', "password": "1234"})
> 3Suppose we want the user’s password to be available only for a specific timeframe (e.g., 60 seconds). With the new hash field expiration feature, we can now do that:
client.hexpire("User1", 60, ["password"])
> [1]Note that in this example, we only set a TTL for a single field, but the command can accept multiple fields at once.
We can check the remaining TTL for the password field:
client.httl("User1", ["password"])
> [46]The reply shows the remaining time in seconds for the field to live. We can also query the absolute expiration time:
client.hexpiretime("User1", ["password"])
> [1757499351]This is a Unix timestamp, which we can easily convert to human-readable time:
date -d @1757499351
> Wed Sep 10 10:15:51 UTC 2025After 60 seconds, if we read the hash:
client.hgetall("User1")
> {b'name': b'Ran', b'age': b'old'}Notice that the password field is no longer present, since it has expired.
Another practical use case is managing a collection of links where each field represents a URL along with its metadata:
links:valkey:blogs -> {
"https://valkey.io/blog/valkey-is-a-key-value-store" ->
{votes: 15, category: "tech"},
"https://valkey.io/blog/valkey-supports-different-ai-workloads" ->
{votes: 42, category: "ai"},
"https://myblog.com/blog/how-to-write-good-valkey-blog" ->
{votes: 7, category: "blog"}
}Here’s how hash field expirations help:
- Each link can have a TTL representing its “relevance window.” If a link hasn’t been accessed within a certain period, it automatically expires.
- Every time a user queries or updates a link, its TTL can be refreshed, keeping active links alive while letting inactive ones naturally fall off.
- Expired links are removed automatically, so you don’t need extra cleanup logic and can focus on active links.
Using Valkey’s HSETEX and HGETEX, we can update a field’s TTL whenever it’s accessed or modified:
# Set or update link metadata with a 30-day TTL
client.hsetex(
'links:user:42',
{
'https://valkey.io/blog/valkey-is-a-key-value-store':
'{"clicks":15,"category":"tech"}'
},
expiry=ExpirySet(ExpiryType.MILLSEC, 30*24*3600))
# Retrieve a link and refresh its TTL
link_data = client.hgetex(
'links:user:42',
{'https://valkey.io/blog/valkey-is-a-key-value-store'},
expiry=ExpirySet(ExpiryType.MILLSEC, 30*24*3600)
)What’s Next?
What we’ve shipped so far is just the first step: the ability to set and control time-to-live at the hash field level. But we’re not stopping here. Future work will focus on two main areas: reducing memory overhead and improving performance. For example, we plan to support compressed encodings for hashes with volatile fields, and to leverage modern CPU features such as memory prefetching and SIMD instructions to speed up operations.
Another critical area for improvement is the active expiration job. Today, all volatile data in Valkey is tracked in unsorted maps (hashtables). The background job must repeatedly scan these unordered sets, which means wasting CPU cycles on entries that aren’t close to expiration. By introducing structured tracking—through the volatile set or even alternative approaches like Hierarchal Time Wheels —we can significantly reduce wasted work and make expiration more efficient at scale.
