
Resharding, Reimagined: Introducing Atomic Slot Migration
Managing the topology of a distributed database is one of the most critical and challenging tasks for any operator. For a high-performance system like Valkey, moving data slots between nodes —a process known as resharding— needs to be fast, reliable, and easy.
Clustered Valkey has historically supported resharding through a process known as slot migration, where one or more of the 16,384 slots is moved from one shard to another. This slot migration process has historically led to many operational headaches. To address this, Valkey 9.0 introduced a powerful new feature that fundamentally improves this process: Atomic Slot Migration.
Atomic Slot Migration includes many benefits that makes resharding painless. This includes:
- a simpler, one-shot command interface supporting multiple slot ranges in a single migration,
- built-in cancellation support and automated rollback on failure,
- improved large key handling,
- up to 9x faster slot migrations,
- greatly reduced client impact during migrations.
Let's dive into how it works and what it means for you.
Background: The Legacy Slot Migration Process
Prior to Valkey 9.0, a slot migration from a source node to a target node was performed through the following steps:
- Send
<target>:CLUSTER SETSLOT <slot> IMPORTING <source> - Send
<source>:CLUSTER SETSLOT <slot> MIGRATING <target> - Send
<source>:CLUSTER GETKEYSINSLOT <slot> <count> - Send
<source>:MIGRATE ...for each key in the result of step 3 - Repeat 3 & 4 until no keys are left in the slot on
<source> - Send
<target>:CLUSTER SETSLOT <slot> NODE <target> - Send
<source>:CLUSTER SETSLOT <slot> NODE <target>
This was subject to the following problems:
- Higher latency for client operations: All client writes and reads to keys
in the migrating hash slot were subject to redirections through a special
-ASKerror response, which required re-execution of the command on the target node. Redirected responses meant unexpected latency spikes during migrations. - Multi-key operation unavailability: Commands like
MGETandMSETwhich supply multiple keys could not always be served by a single node when slots were migrating. When this happened, clients would receive error responses and were expected to retry. - Problems with large keys/collections: Since the migration was performed one key at a time, large keys (e.g. collections with many elements) needed to be sent as a single command. Serialization of a large key required a large contiguous memory chunk on the source node and import of that payload required a similar large memory chunk and a large CPU burst on the target node. In some cases, the memory consumption was enough to trigger out-of-memory conditions on either side, or the CPU burst could be large enough to cause a failover on the target shard due to health probes not being served.
- Slot migration latency: The overall latency of the slot migration was
bounded by how quickly the operator could send the
CLUSTER GETKEYSINSLOTandMIGRATEcommands. Each batch of keys required a full round-trip-time between the operator's machine and the cluster, leaving a lot of waiting time that could be used to do data migration. - Lack of resilience to failure: If a failure condition was encountered, for example, the hash slot will not fit on the target node, undoing the slot migration is not well supported and requires replaying the listed steps in reverse. In some cases, the hash slot may have grown while the migration was underway, and may not fit on either the source or target node.
The Core Idea: Migration via Replication
At its heart, the new atomic slot migration process closely resembles the concepts of replication and failover which serve as the backbone for high availability within Valkey. When atomic slot migration is requested, data is asynchronously sent from the old owner (the source node) to the new owner (the target node). Once all data is transferred and the target is completely caught up, the ownership is atomically transferred to the target node.
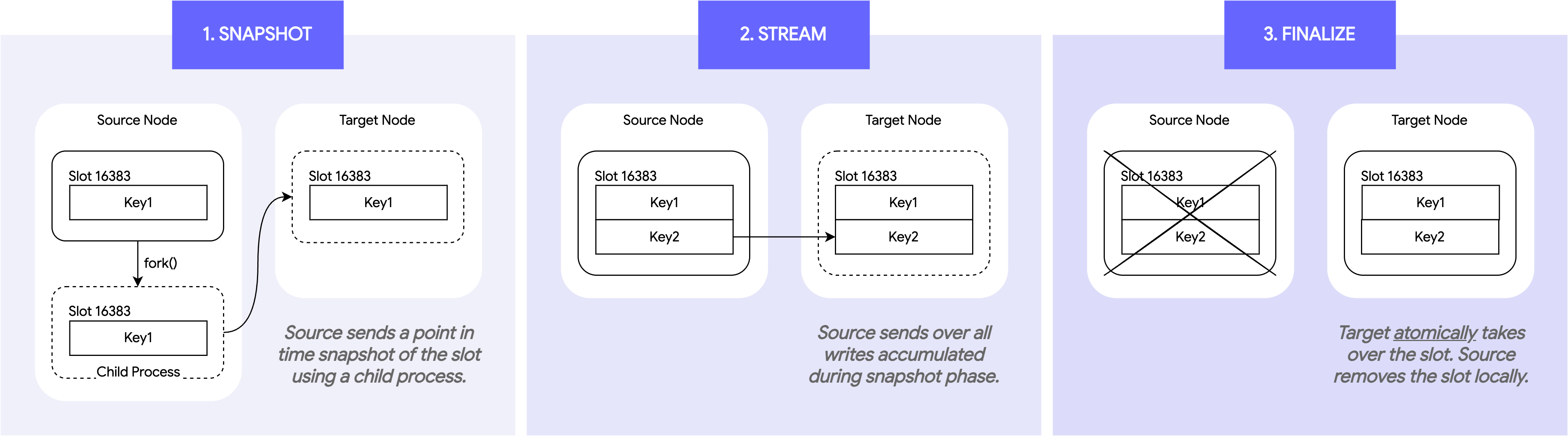
This gets logically broken down into three phases:
- Snapshot Phase: The source node first sends a point-in-time snapshot of all the data in the migrating slots to the target node. The snapshot is done asynchronously through a child process, allowing the parent process to continue serving requests. The snapshot is formatted as a stream of commands which the target node and its replica can consume verbatim.
- Streaming Phase: While the snapshot is ongoing, the source node will keep track of all new mutations made to the migrating slots. Once the snapshotting completes, the source node streams all incremental changes for those slots to the target.
- Finalization Phase: Once the stream of changes has been sent to the target, the source node briefly pauses mutations. Only once the target has fully processed these changes does it acquire ownership of the migrating slots and broadcast ownership to the cluster. When the source node discovers this, it knows it can delete the contents of those slots and redirect any paused clients to the new owner atomically.
Why is this better?
By replicating the slot contents and atomically transferring ownership, Atomic Slot Migration provides many desirable properties over the previous mechanism:
- Clients are unaware: Since the entire hash slot is replicated before any
cleanup is done on the source node, clients are completely unaware of the slot
migration, and no longer need to follow
ASKredirections and retry errors for multi-key operations. - Keys no longer need to be atomically moved: Collections are moved as chunks of elements that are replayed as commands, preventing the reliability problems previously encountered when dumping and restoring a large collection.
- A migration can easily be rolled back on cancellation or failure: Since Valkey places the hash slots in a staging area, they are easily wipe them independently of the rest of the database. Since this state is not broadcasted to the cluster, ending the migration is a straight-forward process of cleaning up the staging area and marking the migration as cancelled. Many failures, like out-of-memory, failover, or network partition can be handled completely by the engine.
- Greatly lowered slot migration latency: Valkey is highly-optimized for
replication. By batching the slot migrations and using this replication-like
process, the end-to-end migration latency can lower by as much as 9x when
compared to legacy slot migration through
valkey-cli.
How to use Atomic Slot Migration
A new family of CLUSTER commands gives you full control over the migration
lifecycle.
CLUSTER MIGRATESLOTS SLOTSRANGE start-slot end-slot NODE node-id- This command kicks off the migration. You can specify one or more slot ranges and the target node ID to begin pushing data. Multiple migrations can be queued in one command by repeating the SLOTSRANGE and NODE arguments.
CLUSTER CANCELSLOTMIGRATIONS- Use this command to safely cancel all ongoing slot migrations originating from the node.
CLUSTER GETSLOTMIGRATIONS- This gives you an observable log of recent and active migrations, allowing you to monitor the status, duration, and outcome of each job. Slot migration jobs are stored in memory, allowing for simple programmatic access and error handling.
Legacy vs. Atomic: Head-to-Head Results
Head-to-head experiments show the improvement provided by atomic slot migration.
Test Setup
To make things reproducible, the test setup is outlined below:
- Valkey cluster nodes are
c4-standard-8GCE VMs spread across GCP’s us-central1 region running Valkey 9.0.0 - Client machine is a separate
c4-standard-8GCE VM in us-central1-f - Rebalancing is accomplished with the
valkey-cli --cluster rebalancecommand, with all parameters defaulted. The only exception is during scale in, where--cluster-weightis used to set the weights to only allocate to 3 shards. - The cluster is filled with 40 GB of data consisting of 16 KB string valued keys
Slot Migration Latency: Who's Faster?
The experiment had two tests: one with no load and one with heavy read/write load. The heavy load is simulated using memtier-benchmark with a 1:10 set/get ratio on the client machine specified above.
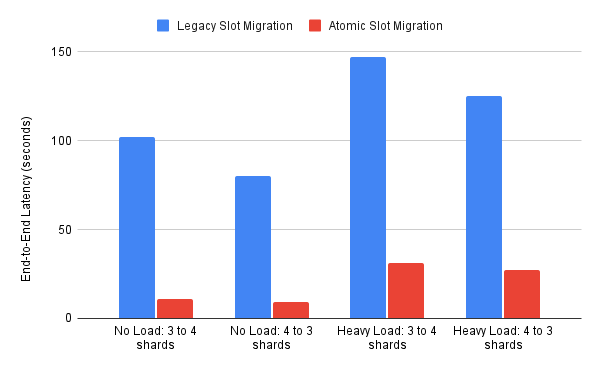
| Test Case | Legacy Slot Migration | Atomic Slot Migration | Speedup |
|---|---|---|---|
| No Load: 3 to 4 shards | 1m42.089s | 0m10.723s | 9.52x |
| No Load: 4 to 3 shards | 1m20.270s | 0m9.507s | 8.44x |
| Heavy Load: 3 to 4 shards | 2m27.276s | 0m30.995s | 4.75x |
| Heavy Load: 4 to 3 shards | 2m5.328s | 0m27.105s | 4.62x |
The main culprit here is unnecessary network round trips (RTTs) in legacy slot migration. Each slot requires:
- 2 RTTs to call
SETSLOTand begin the migration - Each batch of keys in a slot requires:
- 1 RTT for
CLUSTER GETKEYSINSLOT - 1 RTT for
MIGRATE - 1 RTT for the actual migration of the key batch from source to target node
- 1 RTT for
- 2 RTTs to call
SETSLOTand end the migration
Those round trip times add up. For this test case where we have:
- 4096 slots to move
- 160 keys per slot
valkey-cli's default batch size of 10
We need:
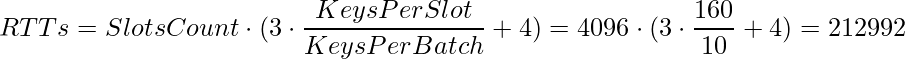
Even with a 300 microsecond round trip time, legacy slot migration spends over a minute just waiting for those 212,992 round trips.
By removing this overhead, atomic slot migration is now only bounded by the speed that one node can push data to another, achieving much faster end-to-end latency.
Client Impact: How Would Applications Respond?
The experiment measured the throughput of a simulated valkey-py workload with 1:10 set/get ratio while doing each scaling event. Over three trial throughput averages are shown below.
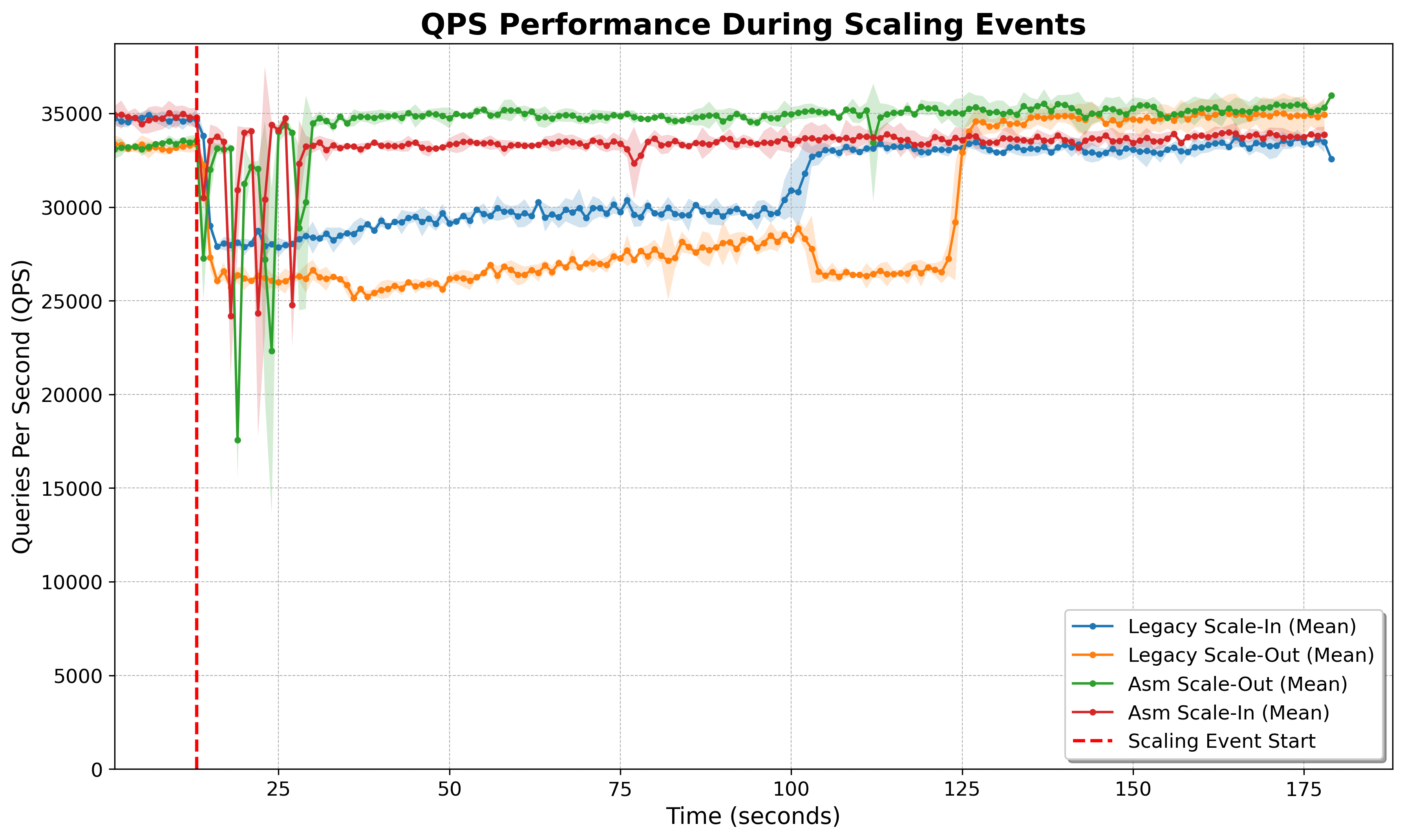
Despite atomic slot migration causing a more acute throughput hit, you can see the recovery of the client application is much faster due to far fewer topology changes and an overall lower end-to-end latency. Each topology change needs to be handled by the Valkey client, so the quicker the topology changes are made, the sooner the impact ends. By collapsing the topology changes and performing atomic handover, atomic slot migration leads to less client impact overall than legacy slot migration.
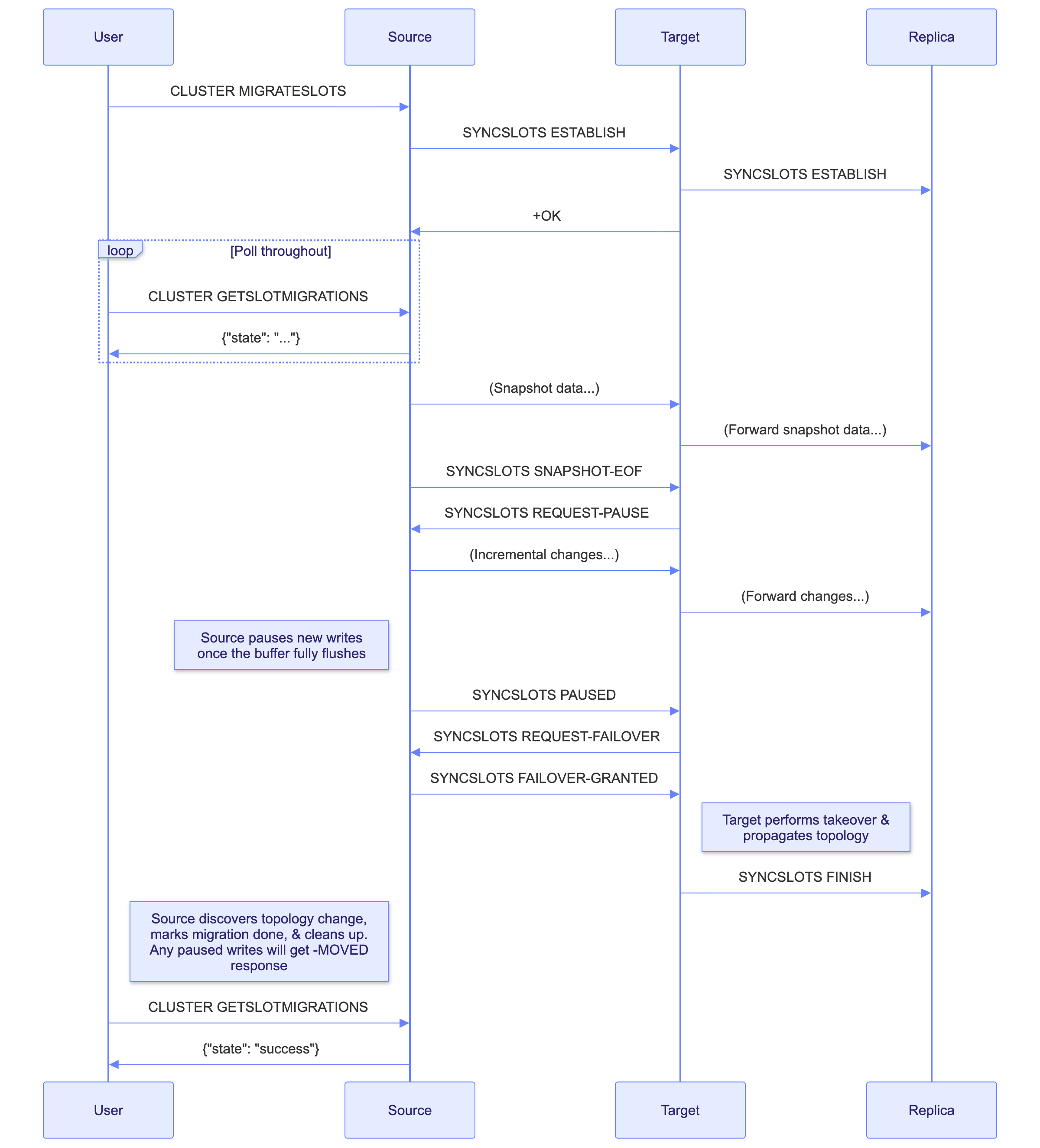
Under the Hood: State Machines and Control Commands
To coordinate the complex dance between the two nodes, a new internal command,
CLUSTER SYNCSLOTS, is introduced. This command
orchestrates the state machine with the following sub-commands:
CLUSTER SYNCSLOTS ESTABLISH SOURCE <source-node-id> NAME <unique-migration-name> SLOTSRANGE <start> <end> ...- Informs the target node of an in progress slot migration and begins tracking the current connection as a slot migration link.
CLUSTER SYNCSLOTS SNAPSHOT-EOF- Used as a marker to inform the target the full snapshot of the hash slot contents have been sent.
CLUSTER SYNCSLOTS REQUEST-PAUSE- Informs the source node that the target has received all of the snapshot and is ready to proceed.
CLUSTER SYNCSLOTS PAUSED- Used as a marker to inform the target no more mutations should occur as the source has paused mutations.
CLUSTER SYNCSLOTS REQUEST-FAILOVER- Informs the source node that the target is fully caught up and ready to take over the hash slots.
CLUSTER SYNCSLOTS FAILOVER-GRANTED- Informs the target node that the source node is still paused and takeover can be safely performed.
CLUSTER SYNCSLOTS FINISH- Inform the replica of the target node that a migration is completed (or failed).
CLUSTER SYNCSLOTS CAPA- Reserved command allowing capability negotiation.
The diagram below shows how CLUSTER SYNCSLOTS is used internally to drive a
slot migration from start to finish:
Get Started Today!
This new Atomic slot migration is a massive step forward for Valkey cluster management. It provides a faster, more reliable, and overall easier mechanism for resharding your data.
So, go download Valkey 9.0 and try Atomic Slot Migration for yourself! A huge thank you to everyone in the community who contributed to the design and implementation.
